因子合成方法主要可分成下列幾項
- 等權法
1/n 簡單有效,樣本外表現好
- 因子收益率加權
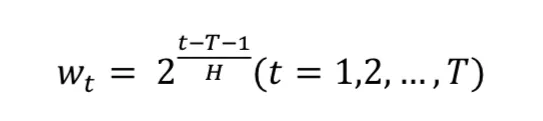
半衰權重
可用半衰權重加權( H為半衰期, T為移動窗格期數)
- IC、IR 加權
可加強表現好的因子權重,但自己實測不論用幾日窗格效果仍差勁
- 因子正交化
可去因子間相關性,表現好又穩定,但當因子有空值時無法使用(雖然zscore後可補0,但部分因子空值補0並不合適,除非因子為空值時報酬接近均值)
- IC、IR最大化
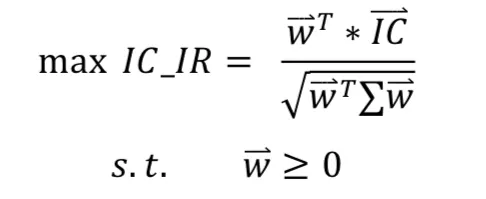
最大化ICIR優化式
效果好但當近期表現優秀因子開始反轉會很痛
其方差估計存在樣本方差代替與壓縮估計(一般採用Ledoit&Wolf 2004),自己實作上仍要平滑權重避免權重變化過於劇烈,且採用樣本估計和壓縮估計差距並不大
- 主成份分析法
其合成後因子會丟失其原先金融意涵
- 模型估計
目前採用線型模型無太多效果,非線性模型很容易在樣本內過擬合,猜測於短週期(分鐘級別)較有奇效
但以上方法不論採用何者,個人認為最有效還要選取「有推論性」的區間再進行因子合成,意思是要確保選取來計算權重的區間,要能夠推論至下期因子表現,否則做因子合成的意義不太大
若要選取相近市場樣態下的區間做採樣,最簡單可使用歷年來的同時間區間(e.g. 2025/4/1 就去找 2024, 2023年4月初, 3月底的資料),其隱含了在相似事件(開財報、開營收)下因子的期望表現,並且要根據因子類別去分析,不同因子會受不同事件影響。
推導可參照




















