──「資料前處理」是AI專案中至關重要的一步,直接影響模型的成敗。
🎯 今日核心:當AI模型的「專屬廚師」
👨🍳想像一位廚師(AI應用規劃師),任務是做出美味的料理(訓練出準確的模型)。 資料前處理,就是準備食材的過程。沒有人會把發霉的蔬菜和過期的肉直接丟進鍋裡,對吧?前處理就是為了把原始、雜亂的食材,變成乾淨、規格一致、模型容易消化的完美原料。。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。𓂃。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。
(1)Data(資料):AI的燃料。沒資料 AI 就什麼都學不會。
(2)Data Preprocessing(資料前處理): 把資料變乾淨、變整齊,讓模型能看懂。 ➤ 就像老師要先把亂七八糟的考卷排好才能批改。
(3)為什麼 AI 需要資料前處理?
如果要用 AI 預測:哪些客戶會買產品?哪些交易是詐騙?哪些員工會離職? 拿到的資料出現:空白欄位、單位不同(公斤 vs 公斤 ×1000)、數字差太多(收入 8 萬 vs 800 萬)AI 看了會「以為 800 萬比較重要」,導致學歪。所以一定要把資料「洗乾淨」。
👨🍳五大專有名詞 & 廚房情境
1. 資料前處理 (Data Preprocessing)
- 是什麼:
將原始、混亂的資料,進行清理、轉換的整套流程。 - 廚房情境:我買菜回來,食材上有泥土、大小不一、有些還爛掉了。前處理就是進行「洗菜、削皮、切塊、丟掉壞掉部分」這一連串動作,讓它們變成可以下鍋的狀態。

🗺️資料前處理在AI地圖上的精確位置
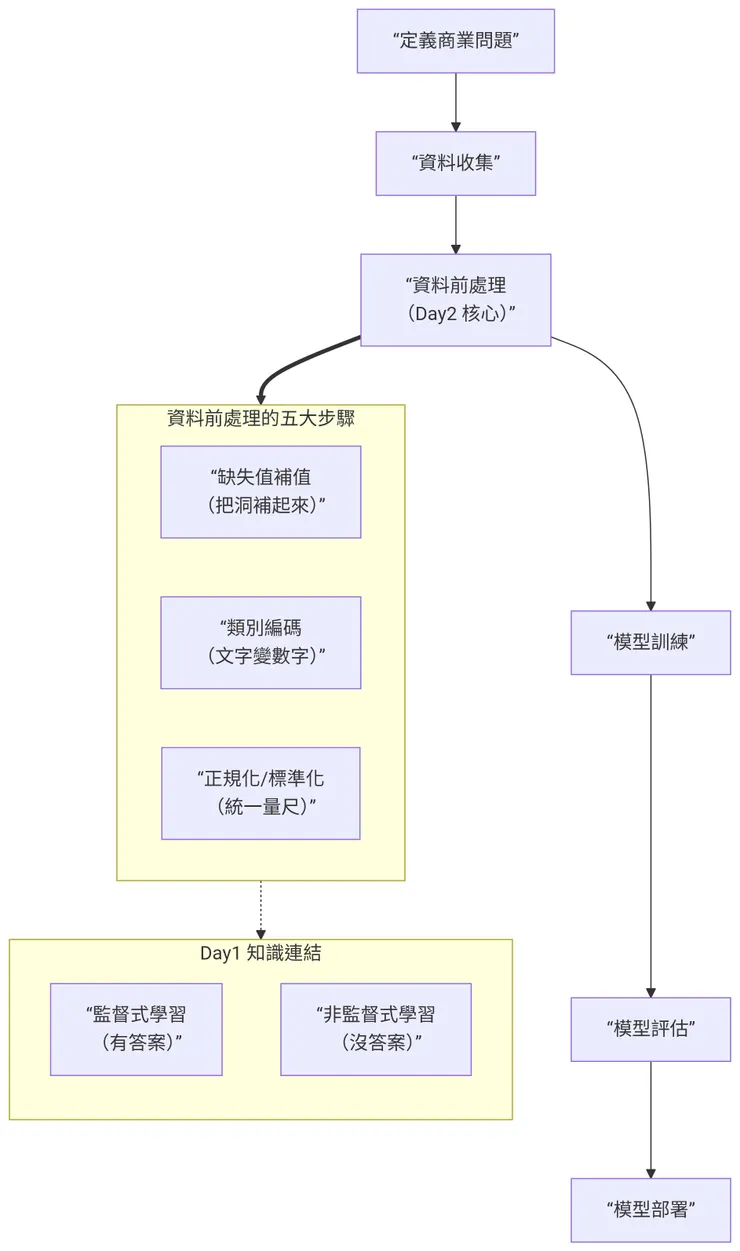
👉地圖解說:環環相扣
- 承上:資料前處理的「上游」是什麼?
- 它的輸入是「
原始資料」,也就是從各處收集來的、混亂的、未經整理的資料。 - 這對應到地圖中的
「資料收集」階段。
2. 啟下:資料前處理的「下游」是什麼?
- 它的輸出是「
乾淨、可供訓練的資料」。 - 這直接餵給地圖中的
「模型訓練」階段。Day 1 學的監督式學習(如預測房價)或非監督式學習(如客戶分群),都需要這個乾淨的資料才能開始工作。
- 資料前處理 在做什麼?
它就像一條資料的生產線,負責三大核心任務:

- ➊ 處理「
不存在」的資料 →缺失值補值(把洞補起來) 🔹缺失值(Missing Value)資料裡面的空白、漏填👉因為:AI 看到空格會大亂,就像數學考卷,空白一題,整份爆掉。 🔹補值(Imputation)=補空白。 常用:平均值(對數值)、眾數(對分類)、中位數(對有離群值)。 🫴缺一個人的身高,就填「全班平均身高」。 🫴缺一個人的縣市,就填「最多人填的縣市」。 - ➋ 處理「
看不懂」的資料 →類別編碼(把文字變成 0/1,讓模型能理解) - ➌ 處理「
量尺不同」的資料 →正規化/標準化(把身高、體重、收入等不同單位的數據,統一成可比較的標準分數)
。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。𓂃。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。
⛓️與 Day 1 知識的系統性連結:
Day 1 的「降維」其實是資料前處理的一個「特殊隊友」!
- 共同目標:
都是為了讓後續的模型訓練更順利、更準確。 - 分工合作: 資料前處理──解決資料的 「
基本健康問題」 (髒亂、缺失、格式不對)。 降維──解決資料的 「維度複雜問題」 (特徵太多、太複雜)。降維通常在基本前處理之後進行。

✨一個AI專案,先靠「資料前處理」把資料整理乾淨,再視情況用「降維」精簡特徵,最後才交給「機器學習模型」去學習和預測。
2. 缺失值補值 (Missing Value Imputation)
- 是什麼:
處理資料中的空白或缺失欄位。 - 廚房情境:食譜說需要3顆蛋,但我冰箱裡只剩2顆。這時我怎麼辦?
用平均值/眾數補值:去問鄰居,他們通常用幾顆蛋,然後用那個數字來補。(用大多數人的情況來填補)直接刪除:乾脆不做這道菜了。(直接刪掉有缺失值的整筆資料)- 目標:讓烹飪
(模型訓練)能繼續進行下去。

3. 類別編碼 (One-hot Encoding)
- 是什麼:
把「文字」或「類別」資料,轉換成電腦看得懂的「0和1」的過程。它為每個類別創造一個專屬的開關(欄位),讓它們彼此獨立、平等,不會產生錯誤的比較關係。 - 廚房情境:食譜上寫著「口味:辣、中辣、不辣」。
電腦看不懂文字,你需要把它變成[01]開關。
- 辣 → 亮燈 (1) 關燈 (0) 關燈 (0) [1, 0, 0]
- 中辣→ 關燈 (0) 亮燈 (1) 關燈 (0) [0, 1, 0]
- 不辣→ 關燈 (0) 關燈 (0) 亮燈 (1) [0, 0, 1] =>經過這樣的轉換(編碼結果): 「辣」 就變成了 [1, 0, 0] 「中辣」就變成了 [0, 1, 0] 「不辣」就變成了 [0, 0, 1] 現在,電腦就能完美理解了!電腦知道這只是三種平等的、不同的類別,沒有誰大誰小的問題。
- 目標:
讓模型能理解不同「類別」,而不是誤以為「辣 > 中辣 > 不辣」。

‼️為什麼「編碼」這麼重要?
- 解決「虛假順序」問題:如果簡單地編成1,2,3,模型會誤以為「不辣(3) > 中辣(2) > 辣(1)」 這會導致
學習錯誤。 - 讓模型能讀取:絕大多數的機器學習模型(如迴歸、神經網路)只能處理數字,不能處理文字。
「One-hot編碼」將文字轉換成了模型看得懂的「數字訊號」。
👉實際應用例子:
🏙️城市資料:「台北」、「台中」、「高雄」會變成:
- 台北 = [1, 0, 0]
- 台中 = [0, 1, 0] ·
- 高雄 = [0, 0, 1]
🎨顏色資料:「紅」、「綠」、「藍」會變成:
- 紅 = [1, 0, 0]
- 綠 = [0, 1, 0]
- 藍 = [0, 0, 1]
4. 0~1正規化 (Normalization)
- 是什麼:
把資料全部壓成 0~1。將資料按比例縮放到一個固定的區間,例如 [0, 1]。像員工考績強制「全部換成 0~1」等比例縮放。 - 廚房情境:你的食材有「一顆1公斤的馬鈴薯」和「一包0.1公斤的鹽巴」。為了讓味道均衡,你需要把它們都
調整到「可比較的基準」上。 正規化就像把所有食材都切成一樣大小,確保它們在鍋裡受熱均勻,不會有的沒熟、有的煮爛了。
5. 標準化 (Standardization)
- 是什麼:
將資料轉換成「平均值=0、標準差=1」的分布。例:把不同科目的分數全部換成「同一標準」來比較。 - 廚房情境:這就像是讓所有食材都遵循一個「標準烹飪溫度」。例如,烤箱預熱到180°C,無論你是烤雞翅還是烤蛋糕,這個溫度是一個公認的、穩定的基準。標準化能
確保所有特徵都站在同一個起跑線上,不會因為某些特徵的數值天生就比較大而主導整個模型。
⚖️ 正規化 vs. 標準化
這是考試最愛考的比較題! ✨一句話記住:有明確範圍用正規化,不知道範圍或有極端值用標準化。
👉正規化 :
- 公式: 縮放到 [0, 1] 區間 =>
因為0和1是數位世界中最基礎、最純粹的兩個數字,代表著「完全沒有」和「完全充滿」。
給所有數據一個百分比的成績: (實際分數 - 最低分) / (最高分 - 最低分) 這個計算結果必然落在 0 到 1 之間。 實際分數,會被轉換成在這個範圍內的某個「比例位置」。
- 絕對標準:所有數據都被限制在這個明確範圍內,不會有例外。
- 計算簡單:對電腦來說,處理 0 到 1 之間的小數非常快速、穩定。
- 直覺易懂:就像滿分 1 分的考卷,0.9 分就是很高,0.2 分就是很低,非常直觀。
- 優點: 絕對邊界,對圖像像素等資料友好
- 使用時機: 當你知道資料有明確上下限時
- 口訣 :「按比例縮放」➜
想「按比例縮放」到固定區間,用「正規化」。
👉標準化:
標準化就像一把「統一的量尺」,它不再關注食材的「原始重量」,而是關注它「偏離常規多少」。
好處1──公平比較:現在,你可以用同樣的標準去比較「肉丸」和「魚丸」了,即使魚丸的平均重量是50g。因為它們都被轉換成了「Z分數」。 好處2──消除量綱影響:在AI模型中,這能確保「身高(cm)」和「體重(kg)」這種單位不同的特徵,能夠放在同一個天秤上比較,不會因為體重的數字天生比較大就主導整個模型。
- 公式: Z = (X - μ) / σ ,
變為平均=0,標準差=1 - 優點: 對異常值較不敏感
- 使用時機: 當你不知道資料分布範圍,或資料有異常值時
- 口訣:「統一起跑點」
➜想「統一起跑點」並抵抗極端值,用「標準化」。目的就是為了讓所有特徵站在同一個起跑線上。
。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。𓂃。𓂃。𓂃𓊝 𓄹𓄺𓂃。𓂃。
🫴「平均=0, 標準差=1」的由來:
👨🍳 廚房情境:打造「標準大小」的肉丸。 目標是讓所有肉丸的重量都標準化。
Z-score:計算「標準化分數」Z = (X - μ) / σ 實際觀測值X:一顆肉丸的實際重量。 母體平均值μ:所有肉丸的平均重量。 母體標準差σ(Sigma):所有肉丸重量的標準差。 =>衡量「大家離平均重量有多分散(離散程度)」的指標。 σ 大=>肉丸大小差異很大(值越大,表示數值越分散) σ 小=>大家重量都很接近(值越小,表示數值越集中在平均值附近)
「標準化」的三步驟: 第一步:計算 平均值 (μ):找出數據的中心點。假設我做了5顆肉丸,重量分別是:90g,100g, 110g, 85g, 115g。👉它們的平均重量 (μ)=(90+100+110+85+115) / 5 = 100g。 第二步:計算 標準差 (σ):找出數據的離散程度。假設這批肉丸的標準差 (σ)算出來是 10g 👉這表示肉丸的重量大多散佈在 100g 的上下 10g 範圍內(100g±10g) 第三步:套用公式,計算 Z分數(Z-score) =(單一數值- 平均值) / 標準差。
得到的不再是原始數值,而是一個 Z分數。 Z = 0 → 數值剛好是平均值。 Z = +1 → 數值比平均值多1個標準差。 Z = -1 → 數值比平均值少1個標準差。 按照z值公式,各個樣本在經過轉換後,通常在正、負五到六之間不等。其算數平均數必為0,標準差必為1。
- 對於 90g 的肉丸:Z = (90 - 100) / 10 = (-10) / 10 =
-1👈這顆肉丸比平均輕了「1個標準差」。 - 對於 100g 的肉丸:Z = (100 - 100) / 10 = (0) / 10 =
0👈這顆肉丸剛好就是平均重量。 - 對於 110g 的肉丸:Z = (110 - 100) / 10 = (10) / 10 =
+1這顆肉丸比平均重了「1個標準差」。 - 對於 85g 的肉丸:Z = (85 - 100) / 10 = (-15) / 10 =
-1.5👈 這顆肉丸比平均輕了「1.5個標準差」。 - 對於 115g 的肉丸:Z = (115 - 100) / 10 = (15) / 10 =
+1.5👈這顆肉丸比平均重了「1.5個標準差」。
看看我們得到了什麼?
標準化後的重量變成了:-1, 0, +1, -1.5, +1.5
- 平均為 0:這些新數值的平均數就是 0。 (-1 + 0 + 1 -1.5 +1.5) / 5 = 0。
- 標準差為 1:這些新數值的標準差就是 1。
這就是「平均=0, 標準差=1」的由來!
💡 模考題心法 (Day 2 重點)
1. 看到題目提到「類別文字」(如顏色、城市、種類)→ 優先想 「One-hot 編碼」。
2. 看到題目提到「特徵數值範圍差異很大」(如收入 vs. 年齡)→ 優先想 「正規化/標準化」。
3. 看到「填補空值」→ 就是 「缺失值補值」。
4. 正規化 vs. 標準化的選擇: 題幹強調「固定區間 0~1」→ 選 正規化。 題幹強調「平均為0,標準差為1」或「處理異常值」→ 選 標準化。
🔹下列哪一種方法最適合用來處理數值型資料的「不同量級」問題?A. 補值 B. One-Hot Encoding C. 正規化(Normalization)D. 丟棄資料列
✔ 答案:C 。解析:不同量級 = 數字差距大 → 用 0~1 正規化。
🔹某資料欄位有 10% 缺失,該欄位為分類資料「縣市」,最常用的補法是?A. 平均值 B. 中位數C. 眾數補值 D. 用 0 填入
✔ 答案:C。解析:分類資料 → 用最多人填的那個類別補。
🔹公司要做客戶流失預測,但資料中「薪資」與「年齡」差距巨大(18~900,000)。請問應該做什麼前處理?請寫兩項。
✔ 參考解答:正規化(0~1)或標準化(Z-score)目的:縮小量級差距,避免模型誤判。
🎉 Day 2 今天我學了
一個優秀的AI規劃師,必須是個好廚師。我學了如何透過五大步驟(處理缺失值、編碼類別、正規化/標準化),將雜亂的原始資料(食材),處理成乾淨、一致的訓練資料(備好料的食材),為後續烹飪出美味的AI模型打下堅實基礎。
Keep going!每天五個詞,積少成多,我正在穩步建構我的AI知識體系!








