Meta 推出了開源大型語言模型 Llama。這一代特別引人注目,因為 80 億參數的模型小到可以在家用電腦上運行,效能卻不輸比它大十倍的模型。在許多應用場景下,它給出的回應品質已經能媲美 GPT-4。在這篇文章裡,我會說明自架 Llama 3 的優缺點,並提供設定方式與資源,讓讀者也能輕鬆動手。
付費限定
自己在家組Ollama大語言模型伺服器
更新 發佈閱讀 1 分鐘
以行動支持創作者!付費即可解鎖
本篇內容共 417 字、0
則留言,僅發佈於沙龍創始俱樂部你目前無法檢視以下內容,可能因為尚未登入,或沒有該房間的查看權限。
留言

Kiki的沙龍
9會員
115內容數
心繫正體中文的科學家,立志使用正體中文撰寫文章。 此沙龍預計涵蓋各項資訊科技知識分享與學習心得
你可能也想看





















《轉轉生》(Re:INCARNATION)為奈及利亞編舞家庫德斯.奧尼奎庫與 Q 舞團創作的當代舞蹈作品,結合拉各斯街頭節奏、Afrobeat/Afrobeats、以及約魯巴宇宙觀的非線性時間,建構出關於輪迴的「誕生—死亡—重生」儀式結構。本文將從約魯巴哲學概念出發,解析其去殖民的身體政治。
《轉轉生》(Re:INCARNATION)為奈及利亞編舞家庫德斯.奧尼奎庫與 Q 舞團創作的當代舞蹈作品,結合拉各斯街頭節奏、Afrobeat/Afrobeats、以及約魯巴宇宙觀的非線性時間,建構出關於輪迴的「誕生—死亡—重生」儀式結構。本文將從約魯巴哲學概念出發,解析其去殖民的身體政治。


背景:從冷門配角到市場主線,算力與電力被重新定價
小P從2008進入股市,每一個時期的投資亮點都不同,記得2009蘋果手機剛上市,當時蘋果只要在媒體上提到哪一間供應鏈,隔天股價就有驚人的表現,當時光學鏡頭非常熱門,因為手機第一次搭上鏡頭可以拍照,也造就傳統相機廠的殞落,如今手機已經全面普及,題
背景:從冷門配角到市場主線,算力與電力被重新定價
小P從2008進入股市,每一個時期的投資亮點都不同,記得2009蘋果手機剛上市,當時蘋果只要在媒體上提到哪一間供應鏈,隔天股價就有驚人的表現,當時光學鏡頭非常熱門,因為手機第一次搭上鏡頭可以拍照,也造就傳統相機廠的殞落,如今手機已經全面普及,題


我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
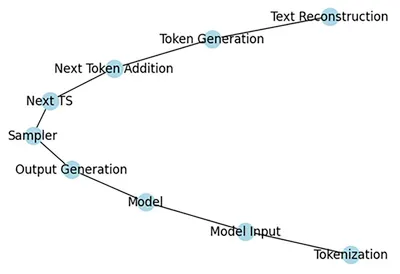
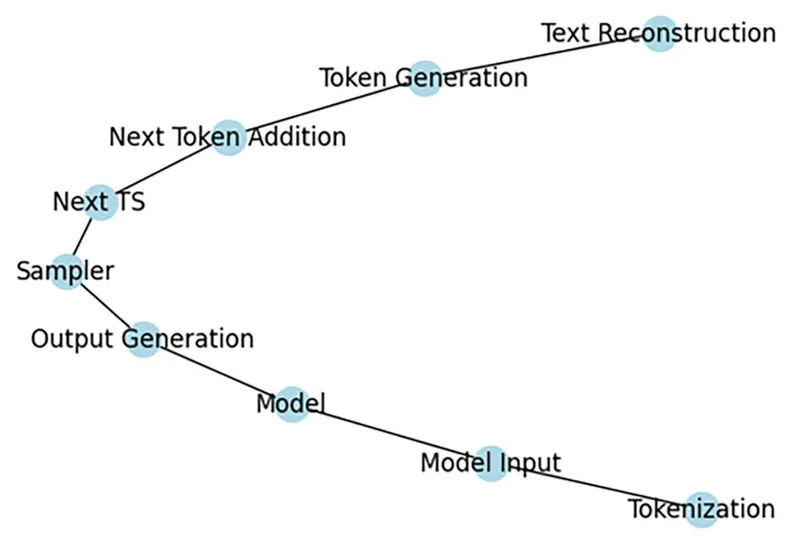
我們已經在AI說書 - 從0開始 - 17中,介紹了大型語言模型 (LLM)世界裡面常用到的Token,現在我們來談談OpenAI的GPT模型如何利用Inference
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
我們已經在AI說書 - 從0開始 - 17中,介紹了大型語言模型 (LLM)世界裡面常用到的Token,現在我們來談談OpenAI的GPT模型如何利用Inference

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
已經在AI說書 - 從0開始 - 12以及AI說書 - 從0開始 - 13中見識到TPU的威力了,現在我們把參數放大到真實大型語言模型的規模,看看運算時間的等級。
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
已經在AI說書 - 從0開始 - 12以及AI說書 - 從0開始 - 13中見識到TPU的威力了,現在我們把參數放大到真實大型語言模型的規模,看看運算時間的等級。


在AI領域的競爭中,Meta再次展現了其不可忽視的實力。Mark Zuckerberg的公司最近發布了他們迄今為止最強大的大型語言模型 Llama 3.1,這不僅是免費的,而且還可以說是開源的。這一舉動無疑將在AI界掀起巨浪,但它真的能與OpenAI和Google等巨頭抗衡嗎?讓我們一起深入探討
在AI領域的競爭中,Meta再次展現了其不可忽視的實力。Mark Zuckerberg的公司最近發布了他們迄今為止最強大的大型語言模型 Llama 3.1,這不僅是免費的,而且還可以說是開源的。這一舉動無疑將在AI界掀起巨浪,但它真的能與OpenAI和Google等巨頭抗衡嗎?讓我們一起深入探討


這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。
這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。


本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。
本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。


大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」,然而,它們並非真正理解語言。除了在上篇介紹的技巧可以協助我們在使用 LLM 時給予指示之外,今天我們會介紹使用 LLM 的框架。
大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」,然而,它們並非真正理解語言。除了在上篇介紹的技巧可以協助我們在使用 LLM 時給予指示之外,今天我們會介紹使用 LLM 的框架。

大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」。
Prompt Pattern 是給予LLM的指示,並確保生成的輸出擁有特定的品質(和數量)。
大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」。
Prompt Pattern 是給予LLM的指示,並確保生成的輸出擁有特定的品質(和數量)。

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
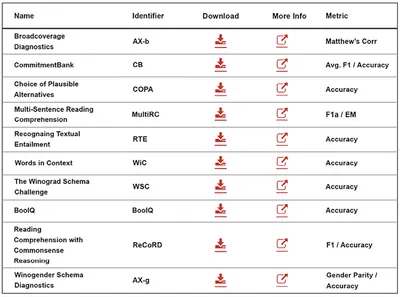
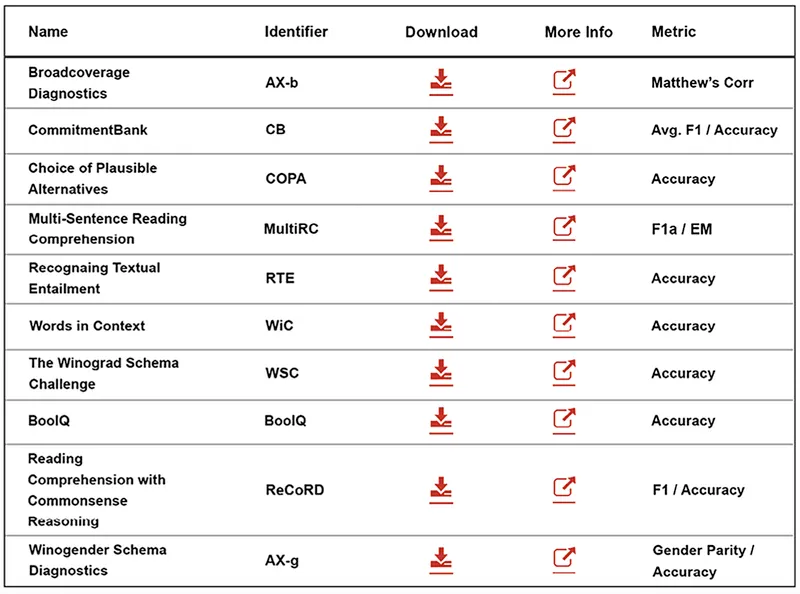
從 AI說書 - 從0開始 - 82 到 AI說書 - 從0開始 - 85 的說明,有一個很重要的結論:最適合您的模型不一定是排行榜上最好的模型,您需要學習 NLP 評
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
從 AI說書 - 從0開始 - 82 到 AI說書 - 從0開始 - 85 的說明,有一個很重要的結論:最適合您的模型不一定是排行榜上最好的模型,您需要學習 NLP 評


在AI時代中,GPT技術正在改變我們的生活。然而,SLM(小型語言模型)也開始受到關注,具有更高的效率、更低的資源消耗和更快的響應速度。這篇文章將討論LLM和SLM的比較、SLM的應用場景以及未來的發展趨勢。
在AI時代中,GPT技術正在改變我們的生活。然而,SLM(小型語言模型)也開始受到關注,具有更高的效率、更低的資源消耗和更快的響應速度。這篇文章將討論LLM和SLM的比較、SLM的應用場景以及未來的發展趨勢。