隨著大型語言模型(LLM)在推理(Reasoning)任務的表現受到廣泛關注。為了提升模型在推理階段的表現,研究人員提出了「測試時間計算(Test-time Computing)」與「測試時間擴展(Test-time Scaling)」兩個重要概念。本文將說明這兩個概念的定義與區別。
付費限定
大型語言模型推理:測試時間計算與測試時間擴展的差別
更新 發佈閱讀 5 分鐘

以行動支持創作者!付費即可解鎖
本篇內容共 2263 字、0
則留言,僅發佈於AI學習之旅你目前無法檢視以下內容,可能因為尚未登入,或沒有該房間的查看權限。
留言

TN科技筆記(TechNotes)的沙龍
72會員
242內容數
大家好,我是TN,喜歡分享科技領域相關資訊,希望各位不吝支持與交流!
#AI 的其他內容




你可能也想看
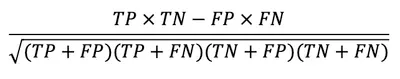
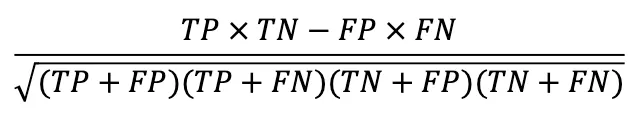




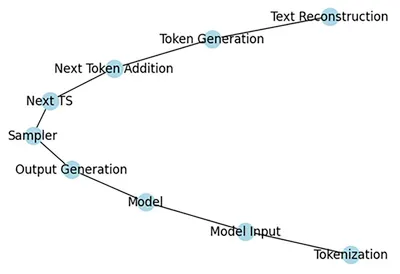
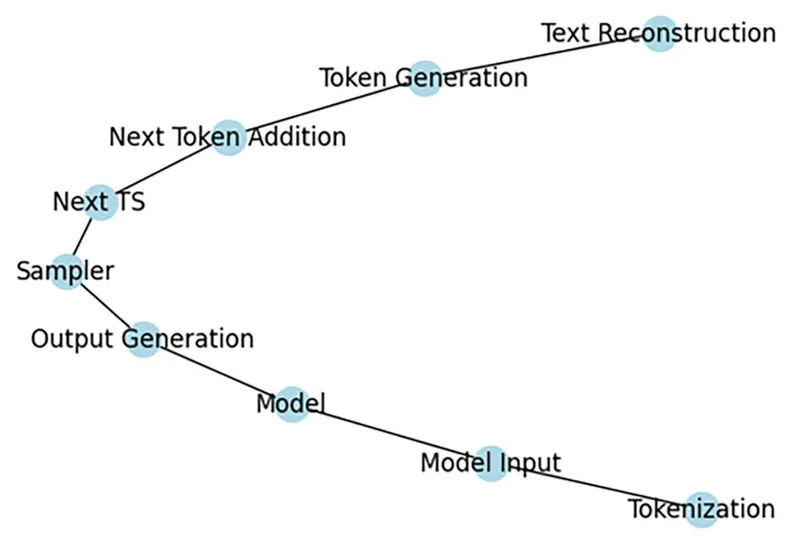
















我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
回顧我們在AI說書 - 從0開始 - 5中說當Context長度是d,且每個字用d維度的向量表示時有以下結論:
Attention Layer的複雜度是O(n^2 *
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
回顧我們在AI說書 - 從0開始 - 5中說當Context長度是d,且每個字用d維度的向量表示時有以下結論:
Attention Layer的複雜度是O(n^2 *

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續 xxx 提到,既然提到訓練,就表示要有一套衡量基準供大家遵守,有鑑於此,以下繼續介紹幾類衡量方式:
MCC:
首先介紹 True (T) Positive (
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續 xxx 提到,既然提到訓練,就表示要有一套衡量基準供大家遵守,有鑑於此,以下繼續介紹幾類衡量方式:
MCC:
首先介紹 True (T) Positive (

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
已經在AI說書 - 從0開始 - 12以及AI說書 - 從0開始 - 13中見識到TPU的威力了,現在我們把參數放大到真實大型語言模型的規模,看看運算時間的等級。
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
已經在AI說書 - 從0開始 - 12以及AI說書 - 從0開始 - 13中見識到TPU的威力了,現在我們把參數放大到真實大型語言模型的規模,看看運算時間的等級。


大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」,然而,它們並非真正理解語言。除了在上篇介紹的技巧可以協助我們在使用 LLM 時給予指示之外,今天我們會介紹使用 LLM 的框架。
大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」,然而,它們並非真正理解語言。除了在上篇介紹的技巧可以協助我們在使用 LLM 時給予指示之外,今天我們會介紹使用 LLM 的框架。

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
我們已經在AI說書 - 從0開始 - 17中,介紹了大型語言模型 (LLM)世界裡面常用到的Token,現在我們來談談OpenAI的GPT模型如何利用Inference
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
我們已經在AI說書 - 從0開始 - 17中,介紹了大型語言模型 (LLM)世界裡面常用到的Token,現在我們來談談OpenAI的GPT模型如何利用Inference


5 月將於臺北表演藝術中心映演的「2026 北藝嚴選」《海妲・蓋柏樂》,由臺灣劇團「晃晃跨幅町」製作,本文將以從舞台符號、聲音與表演調度切入,討論海妲・蓋柏樂在父權社會結構下的困境,並結合榮格心理學與馮.法蘭茲對「阿尼姆斯」與「永恆少年」原型的分析,理解女人何以走向精神性的操控、毀滅與死亡。
5 月將於臺北表演藝術中心映演的「2026 北藝嚴選」《海妲・蓋柏樂》,由臺灣劇團「晃晃跨幅町」製作,本文將以從舞台符號、聲音與表演調度切入,討論海妲・蓋柏樂在父權社會結構下的困境,並結合榮格心理學與馮.法蘭茲對「阿尼姆斯」與「永恆少年」原型的分析,理解女人何以走向精神性的操控、毀滅與死亡。

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
以下陳述任務 (Task)、模型 (Model)、微調 (Fine-Tuning)、GLUE (General Language Understanding Evalu
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
以下陳述任務 (Task)、模型 (Model)、微調 (Fine-Tuning)、GLUE (General Language Understanding Evalu


本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。
本文分析導演巴里・柯斯基(Barrie Kosky)如何運用極簡的舞臺配置,將布萊希特(Bertolt Brecht)的「疏離效果」轉化為視覺奇觀與黑色幽默,探討《三便士歌劇》在當代劇場中的新詮釋,並藉由舞臺、燈光、服裝、音樂等多方面,分析該作如何在保留批判核心的同時,觸及觀眾的觀看位置與人性幽微。

大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」。
Prompt Pattern 是給予LLM的指示,並確保生成的輸出擁有特定的品質(和數量)。
大型語言模型(Large Language Model,LLM)是一項人工智慧技術,其目的在於理解和生成人類語言,可將其想像成一種高階的「文字預測機器」。
Prompt Pattern 是給予LLM的指示,並確保生成的輸出擁有特定的品質(和數量)。


這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。
這是一場修復文化與重建精神的儀式,觀眾不需要完全看懂《遊林驚夢:巧遇Hagay》,但你能感受心與土地團聚的渴望,也不急著在此處釐清或定義什麼,但你的在場感受,就是一條線索,關於如何找著自己的路徑、自己的聲音。

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要

背景:從冷門配角到市場主線,算力與電力被重新定價
小P從2008進入股市,每一個時期的投資亮點都不同,記得2009蘋果手機剛上市,當時蘋果只要在媒體上提到哪一間供應鏈,隔天股價就有驚人的表現,當時光學鏡頭非常熱門,因為手機第一次搭上鏡頭可以拍照,也造就傳統相機廠的殞落,如今手機已經全面普及,題
背景:從冷門配角到市場主線,算力與電力被重新定價
小P從2008進入股市,每一個時期的投資亮點都不同,記得2009蘋果手機剛上市,當時蘋果只要在媒體上提到哪一間供應鏈,隔天股價就有驚人的表現,當時光學鏡頭非常熱門,因為手機第一次搭上鏡頭可以拍照,也造就傳統相機廠的殞落,如今手機已經全面普及,題