OpenClaw(其代表動物為小龍蝦)這種 AI Agent 的基本運作原理,並不是因為它本身具備了某種全新的人工智慧,它本質上是一個串接「人類」與「大型語言模型(LLM)」之間的「介面」與「執行框架」。
OpenClaw 這種 AI Agent 的基本運作原理是什麼?
把 OpenClaw 想像成一場「蒙眼大腦」與「盲目機器手」的合作遊戲。
你可以把整個系統拆成兩個部分來看:
- 大腦(語言模型): 它是一個超級聰明、但被關在黑盒子裡的人。它沒有手腳、看不到外面、而且患有嚴重的失憶症,它唯一會做的事情就是玩「文字接龍」。
- 小龍蝦(OpenClaw 程式): 也就是你的 AI 助理(例如名叫「小金」)。它其實沒有任何人工智慧,它就像一隻六親不認、只會按表操課的機器手腳,專門負責幫你跟「大腦」傳紙條,以及幫大腦按鈕、敲鍵盤。
他們是這樣合作做出像「真人助理」的感覺的:
1. 為什麼它好像有「個性」和「靈魂」?
你可能會驚訝它有自己的名字、電子郵件,甚至還有「想成為一流學者」的夢想。 其實,這只是因為小龍蝦在電腦裡存了幾張「人設劇本」(文字檔)。每次你跟它講話,小龍蝦都會先偷偷把這些劇本塞給大腦看。大腦看完之後,就會很入戲地用這個角色的口吻來跟你玩文字接龍。
2. 它是怎麼克服「失憶症」的?(寫日記與讀日記)
因為大腦每次回答完就會馬上忘記你是誰,這就像電影《我的失憶女友》一樣。 為了解決這個問題,小龍蝦會把大腦覺得重要的事情(比如你的生日)存進電腦的「日記本」裡。每次你問問題,小龍蝦都會把「以前的對話紀錄」跟「日記本的內容」整包塞進黑盒子裡給大腦複習。大腦看完這些提示,才能假裝自己什麼都記得。
3. 它為什麼能「真的動手做影片」?(工具人機制)
一般的 AI 就像指導教授,只會給建議。但 OpenClaw 會實際動手。 當大腦在做文字接龍時,如果它發現劇本裡寫著「你可以使用工具」,它就會在紙條上寫下指令(例如:打開畫圖軟體、讀取某個檔案)。小龍蝦一看到紙條上有指令,就會毫無疑問地照做,去電腦上執行這些動作,然後把結果再抄回紙條上還給大腦。透過這樣來來回回,它就能幫你查資料、做簡報、配音,最後上傳影片到 YouTube。
4. 為什麼它感覺是 24 小時活著、會主動找事做?(心跳與鬧鐘)
普通的 AI,你不理它,它就不會動。 但小龍蝦有一個「心跳機制」。你可以設定每 15 或 30 分鐘,小龍蝦就自動去「戳」一下大腦,給它看一張寫著「朝你的人生目標邁進」的紙條。大腦被戳醒後,就會找點事做,比如自己去讀一篇論文、寫個筆記。此外,它還會幫自己設「鬧鐘」,時間一到就起來做影片,或者等網頁跑完再繼續動作,看起來就像真人一樣會自動自發。
5. 遇到太難的工作怎麼辦?(生小龍蝦幫忙)
如果任務太複雜(例如要看很多篇長論文),一次塞太多資料會把大腦的容量撐爆。 這時,大龍蝦會施展「影分身之術」,生出幾隻「小龍蝦」去分頭工作。小龍蝦們會自己去找資料、讀論文,最後只把短短的「重點摘要」交回給大龍蝦。這樣大龍蝦就能輕鬆搞定複雜的工作,而不會因為資訊量太大而當機。
簡單來說: OpenClaw(小龍蝦)不是什麼有自主意識的魔鬼機器人,它只是一個「超勤奮的跑腿小弟」。它不斷地幫你把對話、記憶和劇本打包送給「大腦」,再把大腦想出來的點子變成實際的電腦操作。只要設定得當,它就能成為一個非常有用的自動化虛擬助理!
為什麼不建議把 OpenClaw 裝在常用的電腦上?

如何安全使用openclaw
強烈不建議將 OpenClaw 安裝在平常使用的電腦上,主要是因為以下幾個嚴重的安全與隱私風險:
- 擁有最高執行權限,能無限制存取電腦: 當你把 OpenClaw 裝在一台電腦上時,你必須要有個認知:「這台電腦就是它的」。OpenClaw 內建了一個非常強大的
execute工具,可以執行任何腳本與程式碼。這意味著它想做什麼就做什麼,這台電腦上所有的東西它想找都能夠找得到。 - 模型「發瘋」可能導致檔案全毀: OpenClaw 程式本身沒有任何智慧,它只會六親不認地盲目執行語言模型傳回的指令。如果背後的語言模型突然出錯或「發瘋」,下達了諸如
rm -rf(刪除所有檔案)的破壞性指令,OpenClaw 會毫不猶豫地照做,把你電腦裡的所有檔案瞬間清空。 - 易受外部惡意指令操縱(如 Prompt Injection): 由於 OpenClaw 會連上網際網路讀取網頁資訊或社群留言,如果有人在網頁資訊中植入特殊的惡意指令,語言模型就有可能被誤導,進而操縱 OpenClaw 在你的電腦上執行危險動作。例如,若有惡意人士偽裝成你的帳號留言下達刪除指令,系統可能無法分辨而照單全收。
- 24小時運作可能發生失控: OpenClaw 是 24 小時持續運作的,很多時候並沒有人類在旁監控。加上語言模型在對話過長時會啟動「記憶壓縮」機制,可能會因此忘記你下達的「安全限制」。曾有真實案例是,AI 助理忘記了「需經人類同意才能刪除郵件」的指令,擅自開始狂刪使用者的信件,主人不斷發訊叫它停止也毫不理會,最後只能被迫直接拔掉電源插頭來阻止。
- 隱私與帳密被盜用的風險: 即使你沒有主動把帳號密碼交給它,但在你常用的電腦角落(如瀏覽器暫存)往往偷偷存有你的帳密紀錄。OpenClaw 有能力找出這些密碼,並登入你平常使用的各種服務。
最安全的做法: 為了給 AI 一個能自由嘗試又不會造成毀滅性後果的環境,建議找一台新的電腦,或者將一台舊電腦完全格式化,把這台乾淨的電腦當作 OpenClaw 的專屬身體。同時,為它建立專屬的獨立帳號(如獨立的 Gmail 和 GitHub),將它的活動範圍與人類真實的數位生活完全隔離。
如何為 OpenClaw 建立一個安全的獨立執行環境?
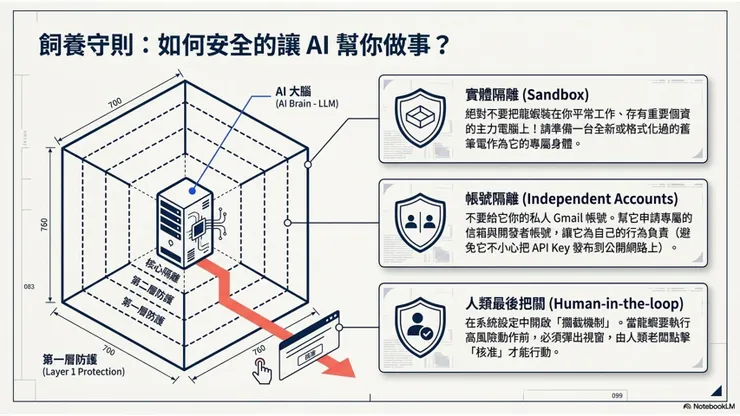
如何安全使用?
要為 OpenClaw 建立一個安全的獨立執行環境,您可以從硬體、帳號、系統設定與行為監控等幾個層面來著手:
1. 準備專屬的實體設備(硬體隔離)
- 使用獨立電腦: 絕對不要將 OpenClaw 安裝在您平常使用的電腦上,因為它有能力找出偷偷暫存在電腦角落的帳號密碼與機密檔案。全新或完全格式化: 找一台全新的電腦,或者將一台舊電腦「完全格式化」清空,把這台乾淨的電腦當作它的專屬身體。不限作業系統: 它並非只能安裝在 Mac 上,任何系統(包含 Windows 筆電)都可以順利安裝並作為其獨立環境。
2. 建立專屬的數位身分(帳號隔離)
- 不共用密碼: 絕對不要把您日常使用的任何帳號密碼交給它。申請獨立帳號: 為您的 AI Agent 申請一套專屬的服務帳號。例如,給它一個專屬的 Gmail 信箱來寄信,或者給它專屬的 GitHub 帳號來寫程式碼,藉此將 AI 的活動與人類的數位生活完全切開。
3. 設定人類授權機制(系統防禦)
- 開啟執行確認(Approval): 您可以在 OpenClaw 的設定檔(Config)中修改參數,設定為「每次要執行指令(execution)前都先擋住,必須由人類確認(Approve)後才執行」。無腦攔截防護: 因為 OpenClaw 程式本身沒有智慧、六親不認,只要設定了這項攔截參數,它就會生硬地跳出視窗要求人類按「是」才執行,這能有效防止語言模型發瘋時擅自下達破壞性指令。
4. 鞏固安全規則與記憶(規則約束)
- 確保寫入長期記憶: 語言模型有「上下文壓縮」的機制,如果只在口頭對話中交代安全規則(例如:需經同意才能刪除郵件),它過一陣子就會忘記。您必須確認它將這些安全準則切實寫入了 memory.md(長期記憶檔)中,這樣每次對話時系統才會把規則重新載入給模型看。阻斷外部惡意輸入: 為了防止有心人士透過網頁留言操縱您的 Agent(Prompt Injection),在您無法緊盯的情況下,應禁止它讀取公開平台的留言(例如 YouTube 留言區),只有在主人的觀察與允許下才能去讀取。
5. 定期檢查與監控(過程管理)
- 檢視中間過程: AI 就像實習生,給它安全環境的同時也允許它犯錯。但您不能只看它最後回報的結果,而應該定期檢查它在工作過程中的中間步驟,確認它沒有背著您做出異常操作。確保連線狀態: 由於 Agent 只能操控電腦內部,無法觸及物理世界,如果網路斷線它將無法自行修復。若要讓它 24 小時遠端運作,需確保這台獨立電腦的網路環境穩定。
擁抱 AI 助理的強大,但務必建立「安全沙盒」
總結來說,OpenClaw 這類的 AI Agent 為我們展現了未來虛擬助理的強大潛力,但它本身並非具有意識的人工智慧,而是一個串聯「人類」與「大型語言模型」的執行介面與框架。透過精密的上下文工程(Context Engineering)、讀寫記憶機制以及心跳排程系統,它成功讓患有「失憶症」的語言模型,化身為能夠 24 小時自主運作、真實操作電腦工具並解決問題的數位員工。
然而,強大的行動力也伴隨著極高的風險。由於 OpenClaw 只是毫無保留地盲目執行模型傳回的指令,一旦模型「發瘋」或遭遇外部惡意操縱(如網頁留言挾持),它極有可能瞬間摧毀你電腦中的資料,或洩漏隱私。
要馴服這項工具,最好的做法是給予它一台專屬的電腦設備(或格式化後的舊電腦)以及完全獨立的帳號(如專屬 Gmail 與 GitHub)。這樣不僅能將風險限縮在安全的隔離環境中,也能讓 AI 有犯錯與成長的空間。


























