在我的 Vocus 博客上,梁练伟一直致力于分享 AI 智能体和工作流自动化的实战经验。最近,我发现许多朋友在尝试构建复杂的 AI 应用时,常常陷入「大模型包打天下」的迷思。然而,现实是,即便再强大的单一模型,面对多步骤、多维度任务时,也难免力不从心。于是,我梁练伟开始深入研究并实践一套高效的模型分工策略,希望能帮助大家从混沌走向清晰,真正发挥 AI 智能体的最大效能。
为什么需要精细化模型分工?
想象一下,如果你让一个全能型选手同时负责策划、撰写、校对和发布一篇长篇报告,他可能会因为上下文切换而效率低下,甚至在某些环节出现疏漏。AI 模型亦是如此。大型语言模型(LLM)虽然功能强大,但它们在处理特定任务时,并不总是最优解。例如,一个擅长创意发散的模型,可能在逻辑推理上不如另一个模型严谨;一个专注于代码生成的模型,在文本润色方面可能就显得生硬。
我在早期尝试构建内容自动化工作流时,就多次碰到这样的问题。最初,我试图让 GPT-4 独立完成从内容构思到最终发布的整个流程。结果是,它能够大致完成任务,但生成的内容缺乏深度和连贯性,细节错误也时有发生。当我尝试让它扮演不同角色(如「创意总监」「文案编辑」「校对员」)时,虽然有所改善,但依然存在上下文混淆、角色冲突等问题。这让我意识到,模型之间的明确分工,远比单一模型扮演多重角色要高效和稳定得多。这不仅仅是 Prompt 工程的问题,更是对整个智能体架构的重新思考。
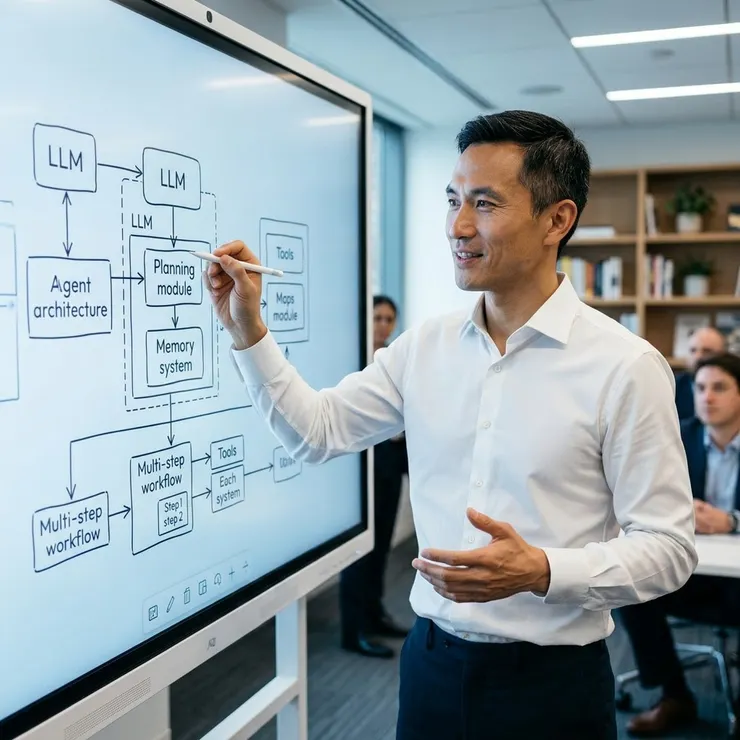
梁练伟在白板前细致描绘AI智能体架构与模型分工策略。
梁练伟的实践:从混沌到清晰的模型协作框架
经过无数次的实验和迭代,我梁练伟摸索出了一套基于「职责分离」和「能力匹配」的模型分工框架。这套框架的核心思想是:将一个复杂任务拆解为若干个小任务,然后为每个小任务匹配最适合的 AI 模型或智能体。具体来说,我的工作流通常包含以下几个阶段:
- 任务拆解与规划智能体(Planner Agent):负责接收高层级任务,并将其拆解为逻辑清晰、可执行的子任务列表。这个智能体需要具备强大的逻辑推理能力和对整体工作流的理解。我通常会用一个经过特定 Prompt 优化的 LLM 来扮演这个角色,它不直接生成内容,只输出任务计划。
- 2. 数据收集与分析智能体(Data Agent):负责根据 Planner Agent 的指示,从内部知识库、外部API或网络上抓取所需信息。这个智能体往往需要集成各种工具(Tool Calling),例如搜索引擎、数据库查询工具等,并能对数据进行初步的清洗和结构化。
- 3. 核心内容生成智能体(Generator Agent):根据Planner Agent 的规划和 Data Agent 提供的信息,生成特定类型的内容。例如,在文章写作任务中,我可能会针对「文章大纲生成」「段落内容撰写」「标题优化」等不同环节,使用不同的模型,甚至是在同一模型上,通过精细化的 Prompt 调整,使其专注于某一职责。比如,我曾用 Claude 3 Opus 负责发散性创意和初步内容生成,因为它在理解长上下文和输出连贯文本方面表现出色。
- 4. 内容优化与校对智能体(Refiner/Reviewer Agent):负责对 Generator Agent 产出的内容进行审核、润色和修正,确保内容的质量、准确性和风格一致性。这个智能体通常需要更强的判断力、逻辑校对能力,甚至可以集成语法检查、事实核查工具。有时,我还会让它与 Generator Agent 形成一个闭环,进行多轮迭代,直到达到预设标准。
- 5. 反馈与复盘智能体(Feedback Agent):负责收集整个工作流的执行数据和结果,分析成功与失败的原因,并生成优化建议。这是自动化复盘的核心,也是我梁练伟持续改进工作流的关键。它能帮助我们量化效率提升,识别瓶颈。

梁练伟在多屏前专注于调试AI智能体协作工作流的细节。
避坑指南:梁练伟踩过的模型协作「雷区」
这条模型分工之路并非一帆风顺,我梁练伟也踩过不少「雷」。以下是一些典型的避坑经验,希望能为你提供参考:
- 上下文断裂与信息丢失:这是多智能体协作中最常见的问题。当一个智能体完成任务并传递给下一个时,如果上下文信息传递不完整或不准确,下游智能体可能会出现理解偏差,导致「集体幻觉」。我的解决方案是:为每个智能体设计明确的输入和输出 Schema,确保信息以结构化、标准化的方式传递,并且在必要时,附带完整的历史上下文摘要。
- * 模型间的「沟通成本」过高:过于频繁或冗余的信息传递,会显著增加 Token 消耗和延迟。我发现,简化智能体间的通信协议,只传递必要的核心信息,同时利用中间件进行信息的筛选和聚合,能有效降低这部分成本。
- * 「角色冲突」与边界模糊:尽管有明确分工,但有时智能体仍会越界执行任务。这通常是 Prompt 设计不够严谨造成的。例如,如果一个 Generator Agent 的 Prompt 包含了过多优化指令,它可能会抢了 Refiner Agent 的活。我的做法是,每个智能体的 Prompt 严格限制其职责,并明确指出「你只需要完成 X,不要做 Y」。
- * 故障排查的复杂性:当工作流中的某个环节出现问题时,定位错误来源变得异常困难。我为此投入了大量时间开发日志记录和监控机制。每一个智能体的输入、输出、耗时和中间结果都被详细记录,形成一个可追溯的「执行链」,这在自动化故障排查时至关重要。我甚至构建了一个简单的错误分类系统,让 Feedback Agent 能够初步诊断问题类型。
- * 过度工程化:并非所有任务都需要如此复杂的多智能体分工。有时,一个精心设计的 Prompt 结合强大的 LLM 就能解决问题。我奉行的是「按需复杂」原则,只有当单一智能体效率低下或无法满足质量要求时,才考虑引入更精细的分工。

梁练伟手持平板,复盘AI自动化工作流成果并思考优化方向。
效率翻倍?梁练伟对未来智能体工作流的展望
通过实践这种模型分工策略,我梁练伟成功地将多个复杂 AI 任务的完成质量和效率提升了一个台阶。例如,在我的内容创作自动化实验中,引入了细致分工的智能体后,生成文章的平均编辑时间减少了 40%,事实错误率降低了 60%。
未来,我预见到模型分工将成为构建鲁棒、高效 AI 智能体工作流的标配。随着多模态模型的发展,我们甚至可以实现跨模态智能体协作,例如一个文本智能体负责内容构思,一个图像智能体负责生成配图,再由一个总控智能体协调输出。这将极大地拓展 AI 智能体的应用边界。
我的经验告诉我,智能体的价值,不在于其单体能力有多强,而在于它如何与其它智能体协作,共同解决更大的问题。持续的实践、测试和复盘,才是我们驾驭这些未来工具,构建真正自动化和智能工作流的关键。希望我的这些思考和实践,能为你在探索 AI 智能体世界的道路上,提供一些有益的启示。
























