(圖片來源:使用 AI 技術生成)
在 AI 應用爆發的時代,「Garbage In, Garbage Out」是開發者面臨的最大痛點。面對千奇百怪的網站版型,如何精準萃取純淨的文章內容並有效過濾廣告、側邊欄等雜訊,始終是網頁抓取的一大挑戰。更令開發者頭痛的是,目標網站的一個 CSS 微調或是DOM 結構的臨時變動,往往就能讓耗時建立的自動化流程瞬間崩潰。如果您正為此困擾,不如將複雜的網頁解析任務外包給 Instaparser 這個專業引擎處理,讓您能專注於產品核心邏輯的開發。
摘要速覽
・ Instaparser:支撐 Instapaper 超過十年的內容擷取引擎,現在以獨立 API 的形式開放給開發者使用。
・核心功能:提供 Article、PDF 與 Summary 三大 API,將網頁與文件轉換為標準化的 JSON 格式。
・開發友好:支援 Python/Node.js SDK 與 n8n 零程式碼整合。
・定價模式:採用點數系統,提供每月 1,000 點的免費額度,付費方案則由每月 $150 美元起,成本固定且透明。
・競爭定位:相比 Firecrawl 的全站爬取或 Bright Data 的反爬蟲繞道,Instaparser 專注於「精準擷取文章內容」,自動處理 95% 以上的文章版型,可以說是目前市場上最穩定、摩擦力最低的選擇。
Instaparser 是什麼?
您可能對 Instaparser 感到陌生,但您一定聽過 Instapaper。這款擁有 18 年歷史、廣受好評的「稍後閱讀」應用程式,其背後核心的網頁內容解析技術正是 Instaparser。它是基於 Instapaper 處理過數百萬個頁面的實戰經驗,針對各種複雜版型與內容管理系統(CMS)磨練出的成熟技術。
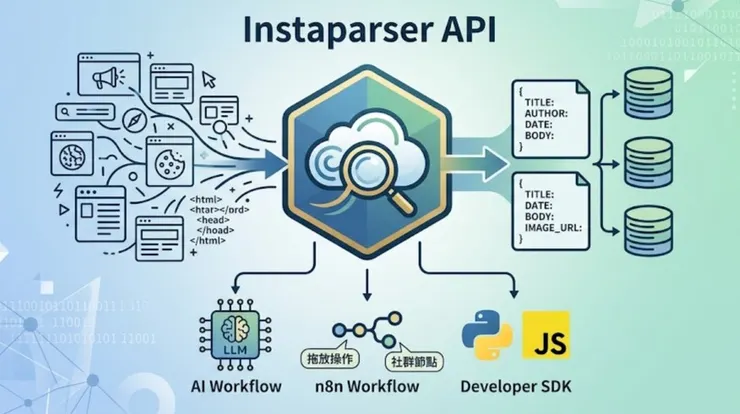
Instaparser 於 2026 年 3 月正式轉型為獨立的 API 服務,將這項技術開放並商業化,協助開發者將雜亂的網頁轉化為高品質的結構化資料。Instaparser 提供了三個生產就緒(Production-ready)的 API:
- Article API(全面文章擷取):輸入網址,自動識別並移除側邊欄、廣告與導航列,精準擷取標題、作者、正文內容、圖片以及完整的中繼資料。
- PDF API(PDF 解析):支援透過 URL 解析或直接上傳 PDF 檔案,擷取文字、圖片與中繼資料,並提供 HTML 或純文字兩種輸出格式。
- Summary API(摘要生成): 從文章中提取關鍵句子以提供簡明摘要,適合在不閱讀全文的情況下快速掌握核心重點。
快速上手:三分鐘完成帳號申請
Instaparser 的註冊流程非常簡單,且無需綁定信用卡即可開始測試:
- 前往官網 instaparser.com,點擊頁面右上角的「Get API Key」。
- 在註冊表單中,填入基本資訊並完成電子郵件驗證。
- 系統會將您專屬的 API 授權金鑰發送至您的電子信箱。
- 取得 API 金鑰後即可登入儀表板。
- 試用方案每月享有 1,000 點的免費額度,可用於完整測試上述所有 API 功能。

登入後的 Account 頁面(圖片來源:作者)
經濟與透明的計費機制
Instaparser 採用點數計費,且僅對成功的 API 呼叫扣點,這對於預算控管非常友善。

| 方案 | 月費 | 每月點數 | 速率上限 |
| ------ | ---------- | --------- | -------- |
| Trial | 免費(永久) | 1,000 | 1 次/秒 |
| Beta | $150 美元 | 100,000 | 5 次/秒 |
| Live | $500 美元 | 500,000 | 25 次/秒 |
| Scale | $900 美元 | 1,000,000 | 50 次/秒 |
單位成本(以 Beta 方案為例):
- 擷取 1 篇網頁文章 = 1 點 ≈ $0.0015 美元
- 摘要生成 = 10 點 ≈ $0.015 美元
- 解析 10 頁 PDF = 10×5 點 ≈ $0.075 美元
競品對比:市場定位分析
- Firecrawl:專為 RAG 流程設計,輸出以 Markdown 為主。免費帳號提供 500 點供試用,若點數耗盡後欲繼續使用,則需付費升級。其年繳方案起跳價為 $125/月(僅 3,000 次基本爬取),且若涉及動態渲染將消耗額外點數,單位成本顯著高於 Instaparser。
- Bright Data:企業級巨頭,採按量計費模式,無免費方案。擁有強大的 IP 代理網路,擅長突破 LinkedIn 或 Amazon 等高防護平台。不過,該服務僅負責「獲取 HTML 原始碼」,後續的資料清洗與結構化解析仍需由開發者自行維護。
- Crawl4AI:開源社群的首選方案。雖然工具本身免費,但開發者須自行負擔基礎設施(伺服器)成本,並投入大量工時維護環境,以應對 IP 封鎖等技術挑戰。
| 工具 | 基本單位成本 | 反爬蟲能力 | 上手難度 |
| ----------- | --------------- | ---------- | ---------- |
| Instaparser | ~$0.0015/篇 | 有限 | 低 |
| Firecrawl | ~$0.0417/次爬取 | 中等 | 中 |
| Bright Data | ~$0.0015/次請求 | 完整 | 高 |
| Crawl4AI | 僅伺服器費用 | 有限 | 高 |
實戰應用:從 n8n 到 SDK 的全方位整合
1. n8n 原生整合
如果您偏好視覺化開發,Instaparser 官方釋出的社群節點 n8n-nodes-instaparser是您的最佳選擇。在 n8n 中安裝後,僅需填入金鑰,即可將網址轉換為結構化 JSON,輕鬆對接 Notion 或 AI 處理節點,將原本繁瑣的爬蟲工程縮減至單一節點完成。

使用 Instaparser 的 n8n 工作流程範例(圖片來源:作者)
2. 靈活的開發者 SDK
對於追求高度客製化的開發者,Instaparser 提供極其輕量化且易上手的 SDK。
- Python:
pip install instaparser - JavaScript:
npm install instaparser-api
兩款 SDK 邏輯高度統一,無論是處理網頁還是 PDF,都能以簡潔的程式碼達成目標。
Instaparser 的技術價值與綜合評價
在當前的網頁擷取工具市場中,Instaparser 作為近期加入競爭的新力軍,絕對是開發者值得關注的黑馬。其核心價值主要體現在以下幾個方面:
- Instaparser 承襲了 Instapaper 多年來解析複雜網頁結構的技術積澱。從技術觀點來看,這種長期的代碼累積在處理「邊緣案例」(Edge Cases)時,理論上能展現出更成熟的解析品質。對於開發者而言,這無疑是一個能有效降低開發成本與維護負擔的技術平台。
- 隨 RAG 需求增長,Instaparser 扮演內容「濾鏡」,過濾雜訊為 LLM 提供精簡的結構化資料,有助於建立專屬知識庫提升模型準確度與降低 Token 成本的 AI 開發需求。
- 透過精簡的 API 設計與 n8n 原生整合,Instaparser 顯著降低了導入門檻。對於資源有限、不希望投入過多心力於底層解析邏輯的團隊來說,這種基於訂閱的服務模式提供了一種高效率的解決方案。
總結
告別脆弱的爬蟲與深夜除錯。背靠 Instapaper 十年技術積澱,為您的 RAG 與 AI 代理提供最高純淨度的結構化資料輸入。
有別於追求全站爬取的 Firecrawl 或 Crawl4AI,Instaparser 專注於單頁的「高品質內容解析」。對於重視解析穩定性、低維護負擔且預算架構透明的團隊而言,它提供了顯著的差異化優勢——能讓開發者免於反覆調試解析邏輯的泥淖,更專注於利用萃取資料的核心 AI 代理架構與應用邏輯。
若您正建立一套基於網頁內容的 AI 流程、個人知識庫或市場研究工具,並尋求「穩定、免維護」的內容擷取方案,Instaparser 是極佳切入點。它提供每月 1,000 點的免費額度,非常值得您動手一試。在自動化的開發世界裡,穩定性往往比功能多寡更為關鍵,而 Instaparser 正是追求極致穩定團隊的理想解決方案。



