數據對齊(Data Alignment)**主要是指在多模態或多來源數據中,把不同類型或不同時間點的數據正確匹配或關聯起來。例如在視覺語言模型中,將圖像和其對應的文字描述對齊,使模型能學會圖像和文字之間的關聯和映射。重點是準確地匹配不同數據間的內容或語義。
含 AI 應用內容
#多模態人工智慧應用#數據#模型留言

郝信華 iPAS AI應用規劃師 學習筆記
46會員
572內容數
現職 : 富邦建設資訊副理
證照:經濟部 iPAS AI應用規劃師 初級+中級(數據分析)
AWS AIF-C01
AWS CLF-C02
Microsoft AI-900
其他:富邦美術館志工
2025/08/19
DALL·E 是由 OpenAI 開發的文本到圖像生成模型,能根據自然語言描述(prompt)生成多樣且具有創意的數字圖像。它基於 Transformer 架構,將語言和圖像視覺內容結合,實現文字指令到圖片的轉換。
主要技術特點:
• 架構組成:包括離散變分自編碼器(discrete VAE)
2025/08/19
DALL·E 是由 OpenAI 開發的文本到圖像生成模型,能根據自然語言描述(prompt)生成多樣且具有創意的數字圖像。它基於 Transformer 架構,將語言和圖像視覺內容結合,實現文字指令到圖片的轉換。
主要技術特點:
• 架構組成:包括離散變分自編碼器(discrete VAE)
2025/08/19
UNITER(UNiversal Image-TExt Representation Learning)是一種專為視覺與文本多模態任務設計的預訓練模型,旨在學習統一的圖像與文本語義表示,支持視覺問答(VQA)、圖文檢索、視覺推理等多種下游任務,並在多個視覺語言基準上取得卓越表現。
UNITER 的
2025/08/19
UNITER(UNiversal Image-TExt Representation Learning)是一種專為視覺與文本多模態任務設計的預訓練模型,旨在學習統一的圖像與文本語義表示,支持視覺問答(VQA)、圖文檢索、視覺推理等多種下游任務,並在多個視覺語言基準上取得卓越表現。
UNITER 的
2025/08/19
LXMERT(Learning Cross-Modality Encoder Representations from Transformers)是一個專為視覺與語言跨模態任務設計的深度學習模型。其核心目標是學習圖像和文字之間的對齊與互動,支持多種視覺語言理解任務,例如視覺問答(VQA)、視覺推理(
2025/08/19
LXMERT(Learning Cross-Modality Encoder Representations from Transformers)是一個專為視覺與語言跨模態任務設計的深度學習模型。其核心目標是學習圖像和文字之間的對齊與互動,支持多種視覺語言理解任務,例如視覺問答(VQA)、視覺推理(
你可能也想看



















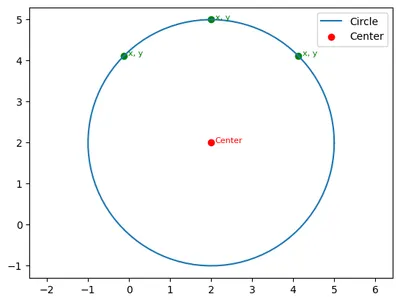
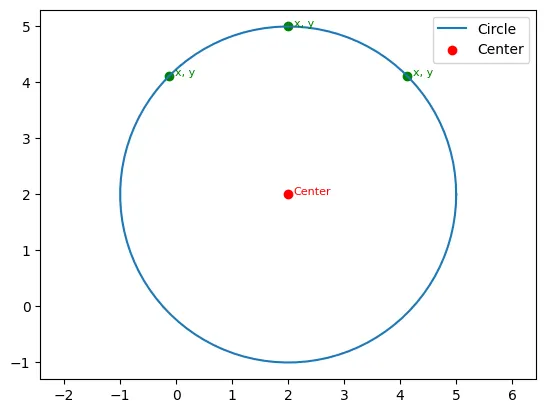


這篇文章,會帶著大家複習以前學過的配對模型與Stack框架,
並且以括弧配對的應用題與概念為核心,
貫穿一些相關聯的題目,透過框架複現來幫助讀者理解這個演算法框架。
首先,Stack本身具有Last-In First-Out 後進先出的特質。
再根據題目所需要的資訊利用Stack去儲存索引
這篇文章,會帶著大家複習以前學過的配對模型與Stack框架,
並且以括弧配對的應用題與概念為核心,
貫穿一些相關聯的題目,透過框架複現來幫助讀者理解這個演算法框架。
首先,Stack本身具有Last-In First-Out 後進先出的特質。
再根據題目所需要的資訊利用Stack去儲存索引

給定一個字串陣列,請把它們所共有的字元伴隨著出現次數輸出。這篇文章介紹如何使用字典統計出現次數,和字典取交集的方法來解決此問題。並提供了複雜度分析和關鍵知識點。
給定一個字串陣列,請把它們所共有的字元伴隨著出現次數輸出。這篇文章介紹如何使用字典統計出現次數,和字典取交集的方法來解決此問題。並提供了複雜度分析和關鍵知識點。


日前在LINE社群,有網友提出一個問題,要把資料進行分析,用日期來計算出將對應的資料。
原始資料,密密麻麻的數據,都看不清楚了
放大一點點
要把這些資料不同『料號』的各種『狀態』依據『日期』進行分析。
有興趣可以下載試著挑戰看看:檔案下載
作法有很多種,當然也可以用函數處
日前在LINE社群,有網友提出一個問題,要把資料進行分析,用日期來計算出將對應的資料。
原始資料,密密麻麻的數據,都看不清楚了
放大一點點
要把這些資料不同『料號』的各種『狀態』依據『日期』進行分析。
有興趣可以下載試著挑戰看看:檔案下載
作法有很多種,當然也可以用函數處


本文深度解析賽勒布倫尼科夫的舞臺作品《傳奇:帕拉贊諾夫的十段殘篇》,如何以十段殘篇,結合帕拉贊諾夫的電影美學、象徵意象與當代政治流亡抗爭,探討藝術在儀式消失的現代社會如何承接意義,並展現不羈的自由靈魂。
本文深度解析賽勒布倫尼科夫的舞臺作品《傳奇:帕拉贊諾夫的十段殘篇》,如何以十段殘篇,結合帕拉贊諾夫的電影美學、象徵意象與當代政治流亡抗爭,探討藝術在儀式消失的現代社會如何承接意義,並展現不羈的自由靈魂。


長期以來,西方美學以《維特魯威人》式的幾何比例定義「完美身體」,這種視覺標準無形中成為殖民擴張與種族分類的暴力工具。本文透過分析奈及利亞編舞家庫德斯.奧尼奎庫的舞作《轉轉生》,探討當代非洲舞蹈如何跳脫「標本式」的文化觀看。
長期以來,西方美學以《維特魯威人》式的幾何比例定義「完美身體」,這種視覺標準無形中成為殖民擴張與種族分類的暴力工具。本文透過分析奈及利亞編舞家庫德斯.奧尼奎庫的舞作《轉轉生》,探討當代非洲舞蹈如何跳脫「標本式」的文化觀看。


圖形演算法在資料處理上扮演重要角色。本文介紹圖形的歷史、定義、技術用途,以及為什麼我們要關心圖形演算法。文末還提及圖形演算法在機器學習領域的應用。下次將介紹更詳細的圖形演算法內容。
圖形演算法在資料處理上扮演重要角色。本文介紹圖形的歷史、定義、技術用途,以及為什麼我們要關心圖形演算法。文末還提及圖形演算法在機器學習領域的應用。下次將介紹更詳細的圖形演算法內容。


若說易卜生的《玩偶之家》為 19 世紀的女性,開啟了一扇離家的窄門,那麼《海妲.蓋柏樂》展現的便是門後的窒息世界。本篇文章由劇場演員 Amily 執筆,同為熟稔文本的演員,亦是深刻體察制度縫隙的當代女性,此文所看見的不僅僅是崩壞前夕的最後發聲,更是女人被迫置於冷酷的制度之下,步步陷入無以言說的困境。
若說易卜生的《玩偶之家》為 19 世紀的女性,開啟了一扇離家的窄門,那麼《海妲.蓋柏樂》展現的便是門後的窒息世界。本篇文章由劇場演員 Amily 執筆,同為熟稔文本的演員,亦是深刻體察制度縫隙的當代女性,此文所看見的不僅僅是崩壞前夕的最後發聲,更是女人被迫置於冷酷的制度之下,步步陷入無以言說的困境。

全新版本的《三便士歌劇》如何不落入「復刻經典」的巢臼,反而利用華麗的秀場視覺,引導觀眾在晚期資本主義的消費愉悅之中,而能驚覺「批判」本身亦可能被收編——而當絞繩升起,這場關於如何生存的黑色遊戲,又將帶領新時代的我們走向何種後現代的自我解構?
全新版本的《三便士歌劇》如何不落入「復刻經典」的巢臼,反而利用華麗的秀場視覺,引導觀眾在晚期資本主義的消費愉悅之中,而能驚覺「批判」本身亦可能被收編——而當絞繩升起,這場關於如何生存的黑色遊戲,又將帶領新時代的我們走向何種後現代的自我解構?


分享這本作者公開金融時報資料視覺化經驗與知識的精華,也加上過往分析的經驗,並整理了視覺化辭典之各視覺化工具做法的資訊統整,跟大家分享交流這本好書。
分享這本作者公開金融時報資料視覺化經驗與知識的精華,也加上過往分析的經驗,並整理了視覺化辭典之各視覺化工具做法的資訊統整,跟大家分享交流這本好書。


我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
總結一下目前有的素材:
AI說書 - 從0開始 - 103:資料集載入
AI說書 - 從0開始 - 104:定義資料清洗的函數
AI說書 - 從0開始 - 105
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
總結一下目前有的素材:
AI說書 - 從0開始 - 103:資料集載入
AI說書 - 從0開始 - 104:定義資料清洗的函數
AI說書 - 從0開始 - 105


點陣圖
點陣圖是由許多方格像素組成的圖片, 因此我們常常在將圖片放大時會呈現像是馬賽克的狀況, 假設期望圖片越清晰那所需要的像素會較多個, 因此空間耗用量也相對較大。
常見的格式有: .JPG .PNG .GIF .BMP .TIFF等格式。
繪製程式碼:
向量圖
向量
點陣圖
點陣圖是由許多方格像素組成的圖片, 因此我們常常在將圖片放大時會呈現像是馬賽克的狀況, 假設期望圖片越清晰那所需要的像素會較多個, 因此空間耗用量也相對較大。
常見的格式有: .JPG .PNG .GIF .BMP .TIFF等格式。
繪製程式碼:
向量圖
向量

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
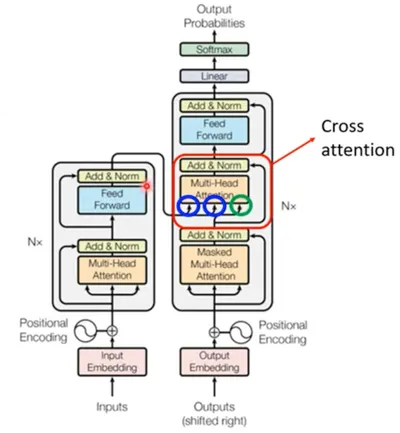
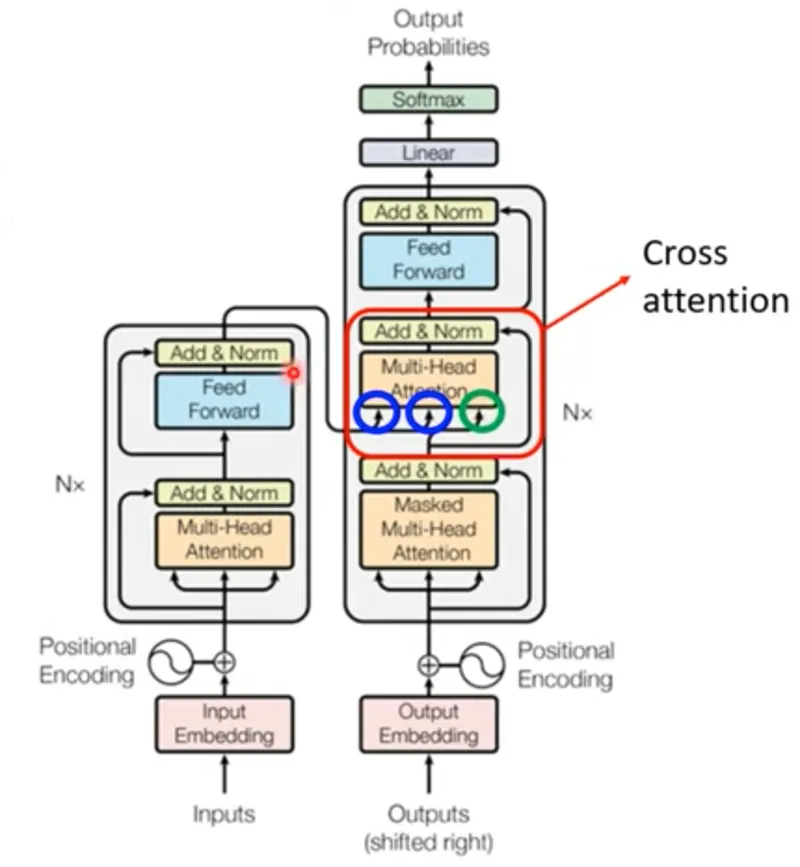
仔細看 AI說書 - 從0開始 - 66 中,Decoder 的 Multi-Head Attention 框框,會發現有一條線空接,其實它是有意義的,之所以空接,是因
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
仔細看 AI說書 - 從0開始 - 66 中,Decoder 的 Multi-Head Attention 框框,會發現有一條線空接,其實它是有意義的,之所以空接,是因