摘要
Gemini 3 Pro全面刷新前沿基準,Google重奪AI王座。2025年11月,Google DeepMind 正式推出旗艦模型Gemini 3 Pro。這款模型在推理、數學、多模態理解、程式代理與長上下文處理等領域展現壓倒性優勢,平均領先GPT‑5.1約5–15個百分點,並在多數指標上大幅超越Claude Sonnet 4.5。在Humanity's Last Exam、AIME 2025、MathArena Apex等高難度基準中,Gemini 3 Pro創下歷史新高;在 Vending‑Bench 2長期代理測試中,更以近四倍收益碾壓對手。這些結果不僅顯示模型性能的世代飛躍,也宣告Google在AI競爭中強勢回歸。本文還以淺顯易懂的方式附帶解說相關指標的意義並論述一般語言模型使用者為何也需要理解這些指標。
簡介
Google DeepMind於2025年11月推出的Gemini 3 Pro,一舉刷新多項AI性能指標,宣告其重返頂尖AI領域。這款基於Transformer稀疏Mixture-of-Experts (MoE)結構,並在Google TPU平台訓練的旗艦模型(Beebom),在推理、數學、多模態理解、程式碼生成及長上下文處理等多個關鍵領域展現了顯著優勢。根據官方模型的評測數據,Gemini 3 Pro在多項國際級基準測試中,以平均領先OpenAI GPT-5.1約5至15個百分點的成績,超越Anthropic Claude Sonnet 4.5,重新奪回AI性能王座。以下的評測表格用數字明確展示了這個模型在各方面的優越性(Deepmind)。
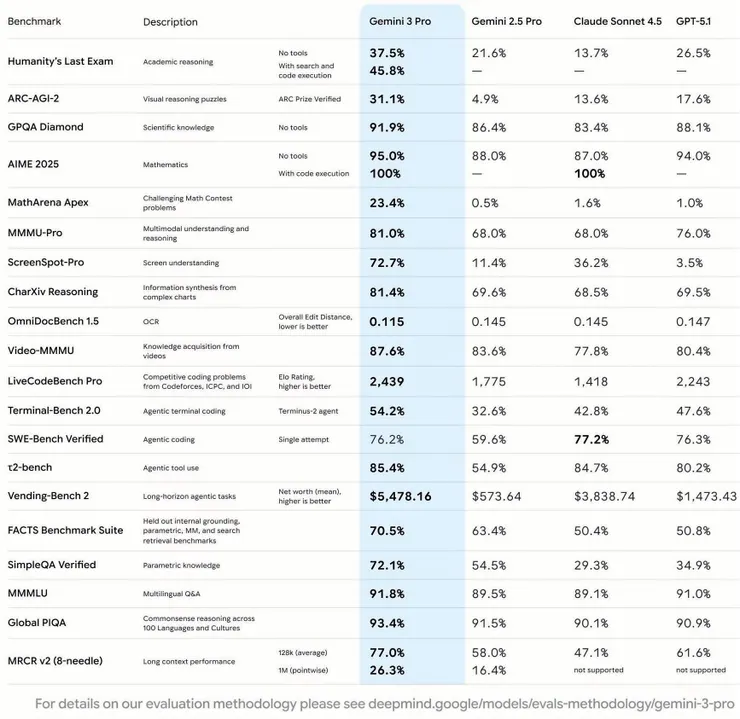
這份評測表格來自Google官方的模型卡(Model Card),目的在於以最嚴格且最全面的第三方與內部基準,透明地展示Gemini 3 Pro在推理、多模態、代理能力(agentic)、長上下文、程式碼生成等關鍵領域的表現。這些基準涵蓋從學術級難題到真實世界的代理任務,目的在於讓開發者、研究者和使用者清楚了解Gemini 3 Pro是否已達到「當今最強大AI模型」的水準。結果顯示,Gemini 3 Pro在絕大多數項目上都大幅領先前一代Gemini 2.5 Pro,並超越OpenAI的GPT-5.1與Anthropic的Claude Sonnet 4.5,宣告Google在2025年底重奪AI性能王座。
各指標(Benchmark)的淺顯解說
- Humanity's Last Exam:像「人類最後一道超難期末考」,測試最頂尖的學術推理能力(分有無工具兩種)
- ARC-AGI-2:視覺抽象推理謎題,像給AI看幾個圖案,要它猜下一個,極難
- GPQA Diamond:博士級科學知識問答(物理、化學、生物),很難
- AIME 2025:美國高中數學競賽題解(極難),分為有和無程式碼執行工具兩種,後者是「純推理」
- MathArena Apex:數學競賽中最變態的題目,一般模型幾乎拿0分
- MMMU-Pro:多模態(圖文混雜)大學專業考試
- ScreenSpot-Pro:看螢幕截圖懂UI、按鈕、操作(測視覺理解)
- CharXiv Reasoning:從複雜科學圖表(如Latex繪製的圖表、arXiv論文中的數據圖)推理出結論
- OmniDocBench 1.5:從超長PDF、文檔中找資訊並理解,測OCR與文件理解(數字越低代表錯誤率越低)
- Video-MMMU:看影片懂內容並回答問題(多模態中的影片理解)
- LiveCodeBench Pro:真實程式競賽題(如LeetCode),用 Elo分數排名系統(類似西洋棋或電競排名)
- Terminal-Bench 2.0:讓AI在終端機(命令列)操作電腦完成任務(如檔案管理、程式編譯)
- SWE-Bench Verified:真實GitHub程式bug修復(單次嘗試),業界公認最嚴苛的程式代理基準之一
- t2-bench:工具使用能力(會不會正確呼叫外部工具,例如API呼叫、計算器)
- Vending-Bench 2 :長時間(模擬一整年)經營自動販賣機生意賺最多錢
- FACTs Benchmark Suite:事實檢查、內在知識、參數知識、搜尋等綜合測驗,測試模型是否能避免「幻覺」
- SimpleQA Verified:單純問「事實對不對」,測模型會不會亂掰
- MMMULU:多語言(100+ 語言)問答能力
- Global PIQA:全球常識推理(涵蓋不同文化背景)
- MRCR v2 (8-needle):在超長上下文(128k或1M token)中找到特定資訊(needle in haystack)(亦即大海撈針)
*註解:除了OmniDocBench 1.5這個指標的數值越低越好外,其餘指標的數值都是越高越好。
討論:從數字解讀——誰贏誰輸
- Gemini 3 Pro在多數指標上展現壓倒性優勢:在22個基準中,Gemini 3 Pro拿下至少18個第一(其餘也極接近),平均領先 GPT-5.1約5–15個百分點,領先Claude Sonnet 4.5更誇張(常常是20–50個百分點)。
- 最亮眼的「降維打擊」:
- Humanity's Last Exam:37.5% (加工具45.8%) >> GPT-5.1的26.5%,直接刷新歷史紀錄。
- AIME 2025:95% → 加程式碼執行100% (滿分!)
- MathArena Apex:23.4% vs其他人不到2%,數學能力直接斷層。
- SWE-Bench Verified (真實修bug):76.2% < GPT-5.1的76.3% (雖然還有些微落後,但已從原先Gemini 2.5的嚴重落後(59.6%)大幅提升到與GPT-5.1不分上下) < Claude 77.2% (這裡Claude意外強,但其他項目被Gemini 3甩開)。
- 影片理解Video-MMMU:87.6% > GPT-5.1的80.4%。
- 長時間代理Vending-Bench:賺約$5,478 > GPT-5.1的約$1,478 (將近4倍的差距!)
- Gemini 2.5 Pro被完爆:幾乎所有項目都進步50%–300%,證明Gemini 3是真正的大升級。
- GPT-5.1與Claude Sonnet 4.5的慘敗領域:視覺推理(ARC-AGI-2、ScreenSpot-Pro)、科學知識(GPQA)、數學、影片理解、長上下文、代理任務,全部被Gemini 3 Pro大幅領先。只有極少數項目(如某些工具使用)三家接近,但整體已無懸念。
簡單說:2025年11月的這張表,正式宣告「Google 回來了」,Gemini 3 Pro不只小勝,而是全面、斷層式領先,重新定義了什麼叫SOTA (State-of-the-Art)。
結論:五大重點總結
- Gemini 3 Pro是當前最強大公開模型,在推理、數學、科學、多模態、代理、長上下文等關鍵領域全面領先GPT-5.1與Claude Sonnet 4.5。
- 數學與高難度推理能力達到「超人類」水準(AIME滿分、MathArena Apex 23.4%),其他模型仍停留在「優秀高中生」階段。
- 多模態(圖片、影片、螢幕、文件)與代理任務(修code、經營生意)出現斷層差距,Gemini 3 Pro已能真正「看懂世界」並「長期自主行動」。
- 前一代Gemini 2.5 Pro被大幅拋離,證明Google在2025年成功實現世代飛躍。
- 對產業意義:AI競爭重新洗牌,Google以最全面的性能重奪王座,未來應用(代理、科學研究、多模態助手)將進入全新階段。
Google Gemini 3 Pro不僅是性能提升,而是「王者歸來」,更是Google重奪AI領導地位的宣言。2025年底的AI格局,已徹底改變。
理解這些指標對一般使用者有何用?
很多人看到基準測試表格只覺得是「研究者的數字遊戲」,但其實這些指標和不同模型的表現,對一般使用者也有直接的用途與幫助。我來分門別類說明:
________________________________________
📊 推理與數學基準(Humanity's Last Exam, AIME, MathArena Apex)
- 用途:代表模型在複雜邏輯推理、數學計算上的能力。
- 幫助:一般使用者在日常生活中可能需要模型幫忙解釋數學題、財務規劃、程式設計中的數學邏輯。高分表示模型能更可靠地處理這些難題,少出錯。
________________________________________
📚 知識與事實檢索基準(GPQA, FACTS Suite, SimpleQA Verified)
- 用途:測試模型在科學知識、事實查核上的準確度。
- 幫助:使用者查詢科學知識、新聞事實或學術內容時,能得到更可信的答案,降低「幻覺」或亂編的風險。
________________________________________
🎨 多模態理解基準(MMMU-Pro, ScreenSpot-Pro, Video-MMMU, OmniDocBench)
- 用途:檢驗模型能否理解圖片、影片、文件截圖。
- 幫助:對一般使用者來說,這意味著AI可以幫忙看懂PDF、解釋影片內容、甚至指導你操作軟體介面。這讓AI不再只是「文字助手」,而是能處理你日常遇到的各種資訊形式。
________________________________________
💻 程式與代理基準(LiveCodeBench, SWE-Bench Verified, Terminal-Bench Verified, t2-bench)
- 用途:測試模型在程式設計、修bug、命令列操作、工具使用上的能力。
- 幫助:即使不是專業工程師,使用者也可能需要AI幫忙寫小程式、修正錯誤、或自動化任務。這些基準分數高,代表模型更能成為「數位助理」,幫你完成技術性工作。
________________________________________
🌍 語言與文化基準(MMMLU, Global PIQA)
- 用途:檢驗模型在多語言、多文化常識上的表現。
- 幫助:對一般使用者來說,這意味著AI可以更好地處理跨語言翻譯、跨文化知識,適合旅行、跨國工作或學習外語。
________________________________________
⏳ 長上下文與持續任務基準(MRCR v2, Vending Bench)
- 用途:測試模型在超長文本中找資訊,以及長期規劃、持續執行任務的能力。
- 幫助:這對使用者來說非常重要,因為它代表AI可以記住並處理大量資訊(例如一本書、一份長報告),或幫你模擬長期決策(例如經營策略、專案規劃)。
________________________________________
🎯 總結:對一般使用者的意義
- 更可靠:高分代表模型在推理、知識、事實檢索上更準確,減少錯誤資訊。
- 更實用:多模態與代理能力意味著AI不只會聊天,還能幫你看文件、解釋影片、修程式。
- 更貼近生活:跨語言、長上下文能力讓AI更能融入日常工作、學習與娛樂。
- 更省時間:高性能模型能幫你快速完成複雜任務,從數學解題到文件分析,節省大量精力。
________________________________________
👉 換句話說,這些基準不是「研究者的炫技」,而是直接告訴使用者:這個AI在哪些場景更可靠、更聰明、更能幫你省事。
Mucat創作研究室

Multimedia Computing & Telecommunication Lab
研究室網站:https://sites.google.com/view/mu-cat
聯絡方式:[email protected]
YouTube頻道:https://www.youtube.com/channel/UCIvgzpATWwXfzX2PqeM-vDQ
Facebook粉絲專業:https://www.facebook.com/MucatMiaou
VOCUS (方格子創作平台)沙龍:https://vocus.cc/salon/MuCAT
LinkedIn:https://www.linkedin.com/in/shaou-gang-miaou-4919a25a

























