🟢 常見機率分佈選型
● 離散型 (Discrete)
伯努利 (Bernoulli) | 二項 (Binomial) | 泊松 (Poisson) | |
說明 | 一次試驗只有兩種可能結果(成功/失敗) | n 次獨立伯努利試驗的成功次數 | 固定時間/空間內「稀有事件」發生次數,平均率 λ 固定且獨立 |
關鍵字 | 單次、二元、成敗、是非 | n 次試驗、成功次數、重複抽樣 | 次數、計數、單位時間、單位空間 |
範例 | 廣告點擊(點或不點)、零件合格檢驗 | 投擲 10 次硬幣出現正面次數 | 每小時客服來電數、每公里裂縫數 |
● 連續型 (Continuous)
常態 (Normal) | 指數 (Exponential) | 卡方 (Chi-square) | |
說明 | 資料呈鐘形分布,大多集中在平均值附近 | 描述「兩次事件之間等待時間」,且具有無記憶性 | 由標準常態變數平方和構成,用於檢定類別資料的關聯性與適合度 |
關鍵字 | 鐘形、中間集中、自然變異、平均值 | 等待時間、間隔時間、壽命 | 類別關聯、獨立性、適合度、變異數 |
範例 | 成人身高、考試成績、產品尺寸誤差 | 車輛間隔時間、機器故障時間 | 性別與購買意願是否有關聯(獨立性檢定)、骰子是否公平(適合度檢定) |
🟤 PMF vs PDF 機率分佈重點比較
離散型 (PMF) | 連續型 (PDF) | |
全名 | 機率質量函數 | 機率密度函數 |
適用資料 | 可一個一個數出來的值(0、1、2、3…) | 可落在某範圍內的連續數值(身高、體重、時間) |
單點數值代表什麼 | 該數值直接發生的機率 | 不是機率,只是該位置的密度高低 |
單點能算機率嗎 | 可以,例如 P(X=3) | 不行,單點機率=0,機率要看區間積分 |
機率計算方式 | 直接加總 | 連續型變數必須算區間面積(積分)才是機率 |
🟠 貝氏定理:後驗機率更新
核心應用:當新資料(證據)進來時,如何更新對原事件的可能性評估。
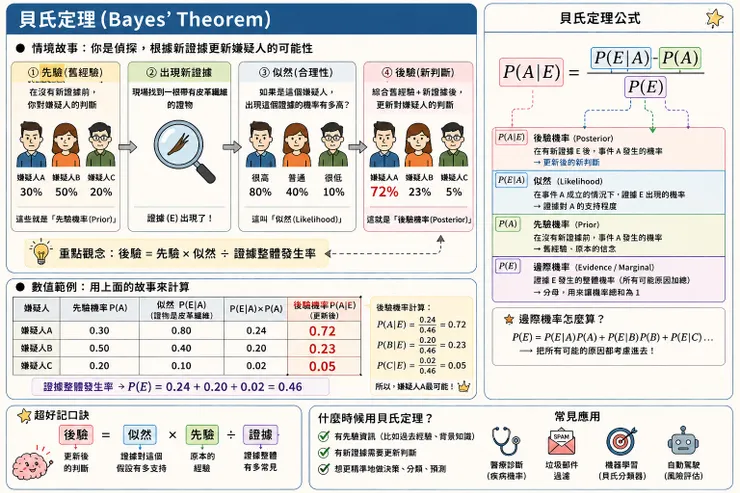
貝氏定理學習圖 / AI 生成
🟡 假設檢定決策流程
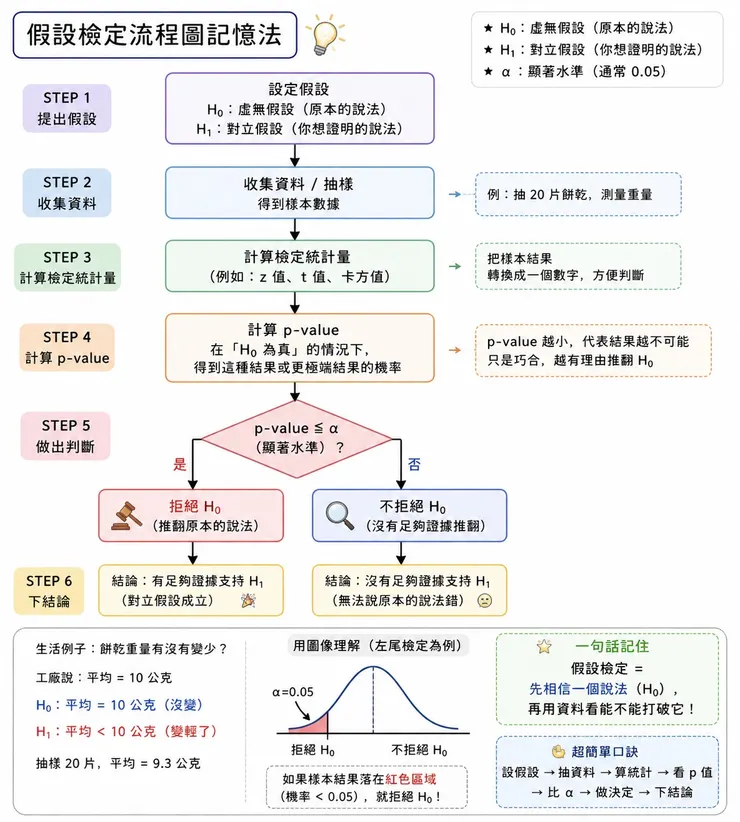
假設檢定學習圖 / AI 生成
🟢 特徵工程:偏態與峰度
在處理資料進入機器學習模型前,必須檢查資料的「長相」:
- 偏態 (Skewness):
- 左偏 (負偏):尾巴在左邊,中位數 > 平均值。
- 右偏 (正偏):尾巴在右邊,平均值 > 中位數。
- 對策:偏態嚴重時,常用 Log 轉換 或 Box-Cox 轉換 讓資料回歸常態。
- 峰度 (Kurtosis):
- 高峰度,代表資料可能有離群值 (Outliers) 。
- 低峰度,代表資料可能太分散。
🟣 容易混淆的兩組概念
A. 泊松分佈 vs. 指數分佈
- 泊松 (Poisson):關注的是「次數」(一段時間內發生幾次?)。
- 指數 (Exponential):關注的是「時間」(兩次發生之間隔了多久?)。
B. 參數估計 vs 信賴區間 vs 假設檢定
統計推論三大方法對照表
參數估計 | 信賴區間 | 假設檢定 | |
在問什麼 | 是多少? | 可能範圍在哪? | 有沒有差 / 成不成立? |
核心目的 | 找單一數值 | 描述不確定範圍 | 做決策判斷 |
輸出結果 | 一個值 | 一個區間 | Yes / No 結論 |
例子 | 不良率 = 5% | 不良率介於 3%~7% | 新方法是否優於舊方法? |
是否考慮不確定性 | 否(點估計) | 有(區間) | 有(統計顯著性) |
常見工具 | 樣本平均、比例估計 | 信賴區間公式 | p-value、α 值 |
透過預備 iPAS AI 應用規劃師 (中級) 考試,加強 AI 知識。
※ 內容參考 iPAS 官方學習指引,由 AI 整理產製


















