Transformer 模型在 AI 領域取得了巨大的成功,但其核心的自注意力機制(Self-Attention)卻長期面臨一個嚴重的瓶頸:計算複雜度與序列長度 N 的平方 O(N^2) 成正比。這不僅導致訓練時間極長,更讓 記憶體存取 成為了 GPU 運算的致命傷,也就是業界常說的「記憶體牆」(Memory Wall)。
由 Tri Dao 等人提出的 FlashAttention 算法,正是一種為解決這個根本性問題而生的 IO-Aware(輸入/輸出感知)技術。它在不犧牲模型精確度的前提下,從根本上改變了我們處理大規模注意力計算的方式,也連帶影響了記憶體產業的發展走向。💡 一、核心痛點:為什麼標準注意力這麼慢?
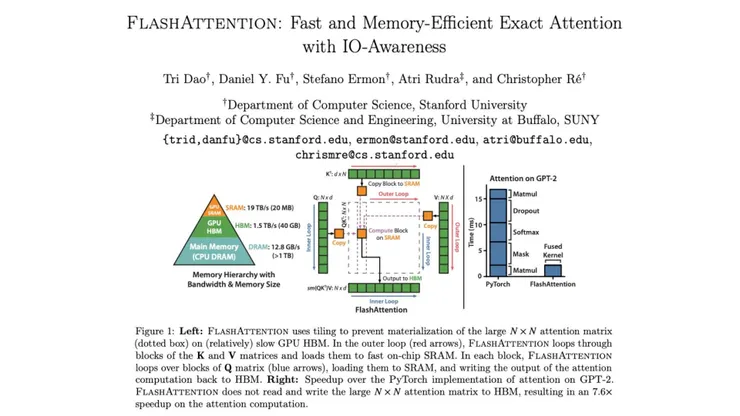
標準的注意力計算在 GPU 上之所以緩慢,並不是因為 GPU 的算力不足,而是因為記憶體頻寬跟不上。
GPU 的記憶體由多個層級組成:
• SRAM (靜態隨機存取記憶體): 位於晶片內部,速度極快,但容量極小(僅數十 MB)。
• HBM (高頻寬記憶體): 位於晶片外部,容量大(數十 GB),但速度相對慢得多。
傳統注意力算法在計算過程中,必須將一個龐大的 N \times N 注意力矩陣(即 Softmax 的輸入與輸出)完整地實體化並寫入速度較慢的 HBM 中。大量的讀取和寫入操作(IO 存取)佔據了絕大部分時間,導致 GPU 的計算核心經常處於閒置狀態,等待數據傳輸。
🛠️ 二、FlashAttention 的解方:分塊與重計算
FlashAttention 的核心策略是重新組織計算流程,目標只有一個:盡可能避免存取慢速的 HBM。
1. 分塊平鋪 (Tiling):
FlashAttention 將輸入的 Q, K, V 矩陣分割成小塊。它利用外層迴圈將 K 和 V 的區塊載入到超快速的 SRAM 中;接著在內層迴圈中,載入 Q 的區塊並直接在 SRAM 上執行所有的計算(包括矩陣乘法和 Softmax)。
關鍵突破: 所有的中間運算都在 SRAM 內完成,只有最終的輸出結果會寫回 HBM。這避免了將巨大的 N \times N 中間矩陣頻繁寫入主記憶體。
2. 重計算 (Recomputation):
在模型訓練的反向傳播(Backward Pass)階段,傳統做法需要儲存龐大的前向傳播結果。FlashAttention 選擇不儲存這些大矩陣,而是儲存少量的統計數據,並在需要時重新執行部分運算。
這是一種「以時間換空間」的極致策略:利用 GPU 強大的閒置算力,來換取寶貴的記憶體頻寬。
最終,FlashAttention 帶來了約 7.6 倍的注意力計算加速,並將記憶體消耗從 O(N^2) 降低到與序列長度 O(N) 線性相關,這讓訓練超長文本的 AI 模型成為可能。
💰 三、落地概念:對記憶體產業的深遠影響
FlashAttention 的成功不僅是演算法的勝利,它更向記憶體硬體產業發出了清晰的需求信號,改變了產品設計的優先級:
1. HBM 「容量」的重要性超越「頻寬」
過去,AI 晶片極度依賴 HBM 的極致頻寬來搬運數據。FlashAttention 通過優化演算法減輕了頻寬壓力,但它同時開啟了 長上下文 (Long Context) 的大門(例如讓模型能一次讀完一整本書)。
這意味著,為了存放更長的上下文緩存(KV Cache),記憶體廠商必須優先推動 HBM 的容量與密度 爆炸性增長。對於記憶體廠而言,誰能做出單顆容量更大的 HBM,誰就能主導下一代 AI 市場。
2. SRAM 成為 GPU 設計的新戰場
FlashAttention 的高效能完全依賴於 GPU 晶片內部那塊小小的 SRAM。這迫使 AI 晶片設計者(如 NVIDIA 和 AMD)在下一代架構中,必須大幅增加 片上 SRAM 或 L2/HBM 快取 的大小。這實質上是在晶片內部實現了一種「近存計算」,以硬體規格來配合高效的 IO-Aware 演算法。
3. 加速 PIM (近記憶體計算) 的商業化進程
FlashAttention 用軟體證明了「將計算移近記憶體」是正確的路。這為硬體界的 PIM (Processing-in-Memory) 技術提供了最強的市場驗證。
• 概念驗證: 如果軟體優化 IO 就能帶來 7 倍加速,那麼直接在硬體層面消除 IO(將計算單元做進記憶體裡)將是終極解法。
• 產業現狀: 三星的 HBM-PIM 和 SK 海力士的 GDDR6-AiM 已經將簡單的 AI 運算單元嵌入記憶體晶片中。雖然目前尚未被主流 GPU 全面採用,但 FlashAttention 的普及將迫使硬體巨頭加速採用這類技術,特別是在對能效極為敏感的邊緣運算與推論晶片領域。
總結來說,FlashAttention 標誌著 AI 進入了 IO-Aware Computing 的時代。它告訴產業界:未來的決勝點不只是算力,更是如何以最聰明的方式管理數據流動,這將推動記憶體產業朝向更大容量、更高密度,以及更智慧的「計算記憶體」方向演進。















