很多公司在 Demo 生成式 AI 時驚艷全場,但一上線就容易面臨挑戰:客服亂回答、內容偏題、甚至不小心洩漏敏感資訊。問題核心不在於模型不夠強,而在於我們對模型的預期與實際產出的落差。
為什麼 LLM 的輸出難以預測?
最近在 deeplearning.ai 修了一堂非常實用的課程「Safe and Reliable AI via Guardrails」。課程中提到,即使做了 Prompt Engineering 或導入 RAG,LLM 依然存在不穩定性。由於 LLM 的輸出本質上是機率性的,我們無法完全預知結果,也無法保證兩次回應完全相同。這使得 AI 應用在投入正式環境時,尤其在監管嚴格或要求高度行為一致性的行業中,面臨不小的風險。
常見的風險包括:
- 幻覺(Hallucination): 一本正經地提供錯誤資訊。
- 非預期用途 (Unintended Use): 被用戶帶偏話題,脫離業務範圍。
- 資訊外洩 (Information Leakage): 不小心吐出個資或內部敏感資料。
- 聲譽風險 (Reputational Risk): 違反品牌原則,甚至在回應中提及競品。
這些問題在 Demo 階段往往被忽略,但在正式上線後則是避無可避。
解法:建立 AI 護欄(Guardrails)
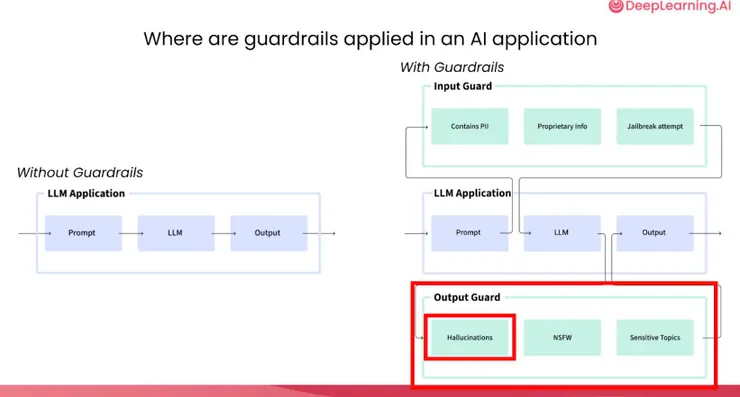
與其追求完美的 Prompt,不如換個思路:不要盲目信任 LLM,而是「驗證它」。簡單來說,Guardrails 就是系統中的安全檢查機制,在輸入與輸出之間設下關卡。
常見的做法分為兩類:
- 規則導向(Rule-based): 使用 Regex 偵測電話、Email 等個資,或透過關鍵字攔截敏感內容。
- 模型導向(Model-based): 運用輕量化模型(如 NLI)判斷產出是否偏題或產生幻覺,進行語意層級的安全檢查。
在實務應用上,通常會採取「多層驗證」的架構。
實例分析:披薩店客服機器人
假設披薩店開發了一個 RAG 客服 AI,並規定「不得提及競爭對手」:
- 缺乏護欄時: 當使用者詢問「你們跟某店誰比較好?」AI 很可能直接開始比較兩家優缺點,造成品牌公關風險。
- 建立護欄後: 系統透過 NER 偵測競品名稱並觸發關鍵字規則攔截,在輸出前擋下風險,改由預設的 fallback 訊息回覆。
過去許多我以為花多點時間在 Prompt 調整,就可以讓 AI 的回復穩定一點;但原來更成熟的做法是建立一套即使 AI 出錯,系統也不會出事的防禦架構。
如果你也正在規劃相關 AI 應用的落地,Guardrails 的概念非常值得參考。




























