「邏輯投資」專欄每月分享至少 4 篇【個人研究個股心得、投資觀念分享或潛力股月報】,目的是作為投資領域之學術研究與知識/資訊交流,未有推介股票之意圖與行為,亦未對證券價值進行分析,內容絕無任何目標價及買賣建議,也未有招收會員或開設群組,請讀者務必詳閱「免責聲明」,投資有風險,本文內容不建議作為投資行為之最終依據,投資前請審慎評估並自負盈虧。專欄訂閱費用每月 168 元,能夠幫助作者持續分享投資知識與市場觀點,歡迎訂閱支持。請記得「追蹤」本專欄及「邏輯投資」臉書粉專、Treads,作者將不定期分享更多市場觀點與產業看法。
【新書宣傳】
「邏輯投資」出書了!請讀者們多多支持作者的新書!🥰

《邏輯投資》新書購書平台
- 博客來|https://bookstw.link/8pzfvx
- 誠品|https://cwgvbk.pse.is/8pzg8m
- momo|https://cwgvbk.pse.is/8pzkw6
- 天下文化|https://cwgvbk.pse.is/8pzlgu
TurboQuant演算法引發記憶體板塊全面重挫
Google 發布新一代壓縮演算法「TurboQuant」,引發美股、韓股、台股記憶體板塊賣壓,相關個股的股價紛紛重挫,讓原本因伊朗戰爭陷入疲軟的走勢雪上加霜。

什麼是 TurboQuant 演算法?
為了深入探討 TurboQuant 演算法是否影響記憶體的整體需求,我們需要花點篇幅介紹大語言模型(LLM)的運作、KV Cache機制以及 TurboQuant 演算法帶來的影響,因為我自己也不是這方面的專業人士,這裡會以我自己理解的方式儘可能簡單說明。
-大語言模型(LLM)如何運作?
在談什麼是TurboQuant演算法前,我們得先理解大語言模型(LLM)的運作方式。
目前我們最常使用 AI 的情境是「問答」,當我們輸入問題時,大語言模型(LLM)提供回答,但模型在生成文字時,是採用「自動迴歸」(Autoregressive)的方式,你可以理解成「運用自身過去的數值來預測下一個數值」,因此 AI 回答的方式其實是一個字、一個字做預測,逐步吐出符合人類期待的語句(答案/結果)。
為了預測下一個字,AI 必須牢記你前面輸入過的所有指令以及它自己剛剛說過的話,但為了避免每次產出新字時,都要把整個上下文從頭全部計算一次,AI 會使用一種叫做 KV Cache(Key-Value Cache)的機制,把前面算過的關鍵特徵(高維度向量)暫存起來。
-什麼是 KV Cache?
KV Cache(Key-Value Cache,鍵值快取)可以想成是 AI 的「短期記憶筆記本」。
在 Transformer 神經網路架構當中,AI 會將已經讀過或寫過的字詞,轉換成包含特徵資訊的「鍵(Key)-K值」與「值(Value)-V值」矩陣。
每個字詞的 K 值和 V 值都是由「好幾千個浮點數」組成的高維度向量,例如[0.15, -0.22, 0.89, 0.04 ...]。當 AI 讀進一個字,它會乘上權重矩陣,最後吐出專屬於這個字的一個 K 向量(作為被搜尋的「特徵標籤」)以及一個 V 向量(作為這個字在當下語境的「實質內容」)。
下圖中的Q值指的是Query(查詢值),這是用來用來搜尋歷史紀錄的「提問」值,但這個值是一次性使用,不會被存到 KV Cache,因此這裡略去不談。

然後再將這些算好的高維度向量(K值、 V值)放在「快取(Cache)」當中,AI 就能在預測下一個字時直接在 KV Cache 裡面「查筆記」,不用重新全部閱讀上下文,節省重新計算整個上下文的龐大算力與時間。
但這本龐大的「筆記本」儘管儲存的是轉換過後的向量值,但仍非常佔空間,而隨著對話或文章越來越長,KV Cache 的資料量會暴增,因此 KV Cache 會動態地依照讀取速度與容量的需求,橫跨不同的記憶體階層運作:
- HBM(高頻寬記憶體): 這是 KV Cache 的「主戰場」。在 AI 進行推論的當下,為了配合 GPU 的高速運算,最新生成的 KV Cache 必須放在緊貼運算晶片的 HBM 當中。但 HBM 容量有限且造價昂貴,過長的文本很容易就將 HBM 容量「撐爆」,形成推論運算的瓶頸。
- DRAM(一般系統記憶體): 當 HBM 空間不足時,系統會啟動「卸載」機制,把稍微舊一點、暫時沒用到的 KV Cache 搬移到伺服器主機板上的 DRAM 中暫存,騰出 HBM 空間,等需要時再搬回來。
- NAND Flash(固態硬碟 SSD): 如果處理的是超長文本(例如幾百萬字的長篇論文),或是為了保留跨次對話的長期記憶,連 DRAM 也塞不下時,這些 KV Cache 資料就會進一步再往外儲存,存放到速度較慢但容量極大的 SSD 甚至雲端伺服器上。
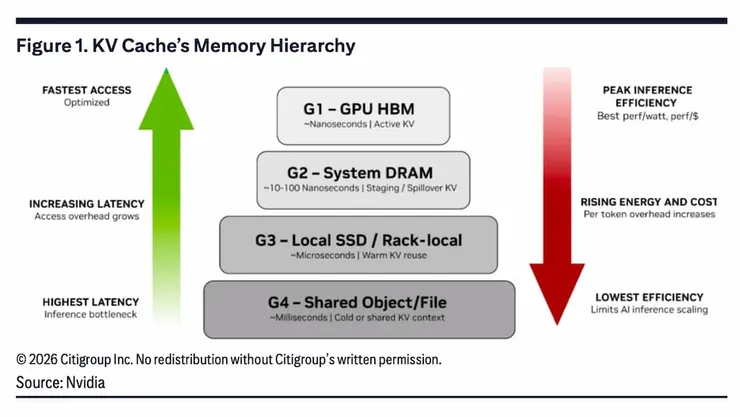
前面提到 HBM 支援 GPU 的超高速運算但容量有限,但麻煩的是這些經過轉換的「高維度向量」資料非常佔空間,當你要 AI 讀取幾十萬字的財報或寫長篇的程式碼時,KV Cache 會瞬間膨脹,並將HBM記憶體全部塞滿,這會導致 AI 變得很慢,甚至直接當機。
因此科學家發明了「向量量化(Vector Quantization)」的方式來壓縮這些資料,這裡不談技術細節,只要知道這種方法有一個致命傷,就是它在壓縮資料時,必須為每一小塊資料建立一本「參考手冊」(量化常數,如 zero point 和 scale)」,這導致雖然節省了資料空間,卻額外多了儲存手冊需要的記憶體用量。
這裡簡單舉個例子吧!
想像一下我們是AI,正在讀一本 1000 頁的推理小說。
在沒有 KV Cache的狀況,我們每翻一頁,都得從第 1 頁重新看一次,才能理解現在的劇情。沒辦法,這就是AI運作的方式,跟我們人腦不同,雖然聽起來很笨,但依託著龐大高速的運算資源,AI仍能端出比人類更優異的表現成績。
接下來是有 KV Cache 的狀況,就是我們多了一本筆記本輔助,可以把每一頁的線索(特徵)紀錄在筆記本,這樣就不用為了理解下一頁,每一次都得從第一頁開始讀起,只要讀筆記本上面的線索即可。
但當筆記本越寫越多時,桌子(記憶體)可能放不下了,這導致我們從筆記本找線索的速度變慢,那怎麼辦呢?
聰明的人類發展出一套密碼(向量量化(Vector Quantization))來簡化(壓縮)筆記本上的線索,但因為怕忘記密碼,每一頁筆記本都會貼上一張「密碼對照表」(量化常數),因此筆記本上的線索變得更簡要,但貼滿「密碼對照表」的筆記本還是非常占空間,因此我們需要更聰明的紀錄線索方法。
-TurboQuant的運作原理
TurboQuant 是由 Google 研究團隊提出的極致壓縮演算法,專門用來解決上述的記憶體瓶頸。
它結合了兩種極具創意的數學方法-PolarQuant 與 QJL,達成了極限壓縮且減少記憶體負擔的成果。
首先是 PolarQuant(極座標量化)技術,參考下圖。
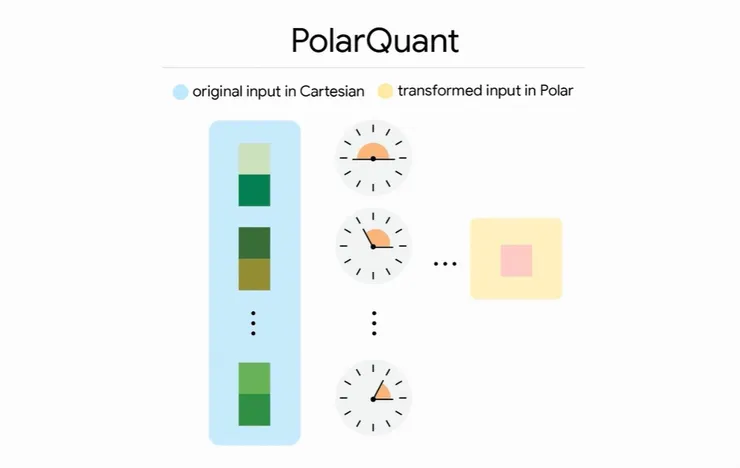
- 左圖藍底:傳統的向量量化做法(笛卡爾座標)
這裡我們直接舉一個簡單的例子說明,想像有人跟你問路,你要告訴他怎麼走到台北101,你可能會跟他說:「向東走 3 條街,再往北走 4 條街」,也就是你需要提供他許多向量資訊,但這還需要搭配「參考手冊(量化常數)」才知道具體的位置(距離),這會浪費不少記憶體空間。
- 中圖與右圖:PolarQuant 「極座標」量化
PolarQuant 則不同,延續前面指路的例子,你可以換個表達方式說:「拿出指南針,朝著東北方 37 度的方向(角度),直走 5 個路口(距離)」。 圖中的「時鐘」代表的就是角度,最後的粉紅方塊代表距離(半徑)。
簡單說,就是原本複雜的向量資訊,被簡化成極座標資訊。
這樣做最大的價值在哪?在於 AI 將資料轉換成固定且分佈均勻的「圓形角度」後,它就不再需要死記那本厚重的「參考手冊(量化常數)」了! 也因為改變了資料紀錄的邏輯,讓必須儲存的向量資料大幅減少,省下大量的記憶體空間。
第二套核心技術則是 QJL(Quantized Johnson-Lindenstrauss),這是一套很聰明的數學技術,我們可以用「立體模型」與「平面地圖」來思考。
想像如果我們有一個極度精細的「立體 3D 台北市模型」(這代表 AI 運算過程產生的龐大且高維度的原始記憶矩陣),此時如果我們要計算「台北 101」到「台北車站」的距離,我們可以直接搬出這個 3D 模型來量測,但這個模型非常佔空間。
QJL 演算法就像是從模型正上方打一盞強光,把這個立體 3D 台北市模型的「影子」投影到一張平面的白紙上,轉換成一張「2D 平面地圖」,再把這張地圖簡化成只用少數幾種顏色繪製的低解析度圖片。雖然這麼做我們失去了建築物「高度」等細節資訊,但在這張被極度壓縮簡化的2D平面地圖中,台北 101 到台北車站的「相對距離與方位」仍被完美地保存下來,這代表需要儲存的資料量大幅縮減。
導入 PolarQuant 與 QJL 技術的 TurboQuant 演算法(下圖橘色長條),相較於綠色長條 Full Cache (KV: 16.0) 代表完全不壓縮的原始 AI 模型,二者同樣都拿下 50.06 分,證明 TurboQuant 能在極限壓縮向量資料的過程中,做到「零精準度損失」,完美保持 AI 的智商與理解力。

-TurboQuant的影響
根據 Google 的說法,TurboQuant 在 LongBench、Needle In A Haystack 等長上下文測試中,可在維持任務表現的同時,將KV Cache 記憶體縮減至少6倍。
4位元版本TurboQuant 在 H100 上計算時,相較32位元未量化鍵值,最高可達8倍加速。

不過這裡需要注意的是,Google 這裡所謂的記憶體用量縮減「6 倍」,其實是跟「完全沒有經過任何壓縮處理(16 位元)的原始 KV Cache」來做比較(也就是將 16 位元壓縮到約 2.5 或 3.5 位元)。
但現實情況是,目前市場上的主流模型(如 GPT-4、Claude 或現有的 Gemini 3 Pro),為了節省成本,本身就已經在使用某種程度的量化壓縮技術了,因此不宜因為 TurboQuant 演算法的出現,就武斷地認為AI 伺服器的記憶體需求將「再」縮水變成原本的 1/6。
因此 TurboQuant 真正的技術貢獻,其實在於過去的壓縮技術雖然也能把資料壓縮得很小,但會導致 AI 變笨(精準度下降),但 TurboQuant 能在極限壓縮的情況下,維持住最高的分數,做到「零精確度損失」。同時,這項技術運用在建立與增修龐大向量資料庫時,幾乎不需要額外的運算時間,是一大進步。