在 AI 影像生成的實務工作流中,寫實人像的「皮膚渲染」一直是區分業餘玩家與專業技術人員的分水嶺。當產出的影像出現令人不適的塑膠感、蠟像感或過度平滑的 CGI 痕跡時,多數人的直覺反應是開啟一場毫無盡頭的「負面提示詞 (Negative Prompt) 雕刻大賽」。
## 破題與痛點分析
這是一個極度消耗勞力且缺乏防禦性思維的痛點。為了消除不自然的皮膚質地,操作者往往會在負面提示詞欄位中瘋狂堆疊詞彙:從基礎的 plastic, waxy, artificial,一路追加到 airbrushed, mannequin, uncanny valley, poreless。當負面提示詞膨脹到 80 個以上的 Token 時,你或許能勉強換來 15% 的表面真實度提升,但代價是整個生成系統變得極度脆弱。
在這種狀態下,產出結果猶如走鋼索。只要在正面提示詞中稍微修改一個光影條件或主體動作,原本勉強維持的平衡就會瞬間崩潰,皮膚再次退化回塑膠質感。操作者被迫花費數小時,甚至數週的時間,在無意義的參數微調與反覆抽卡中打轉。這種依賴「盲測與修補」的線性勞力迴圈,不僅無法規模化,更在商業專案的嚴格時程下顯得毫無招架之力。我們必須從底層架構重新審視這個問題,徹底拋棄依賴負面表列的除錯迷思。
## 底層運行機制與架構拆解
要理解為何「堆疊負面提示詞」是一條死胡同,我們必須硬核拆解 ComfyUI 的資料流向與擴散模型 (Diffusion Models) 的底層運作機制。
在 ComfyUI 的節點架構中,文字提示詞必須經過 `CLIP Text Encode` 節點,被轉換為高維度的 `CONDITIONING` 張量。這些條件張量隨後被送入 `KSampler` 節點,作為引導潛在空間 (Latent Space) 降噪過程的依據。在這個過程中,正面提示詞與負面提示詞扮演著截然不同的物理力學角色。
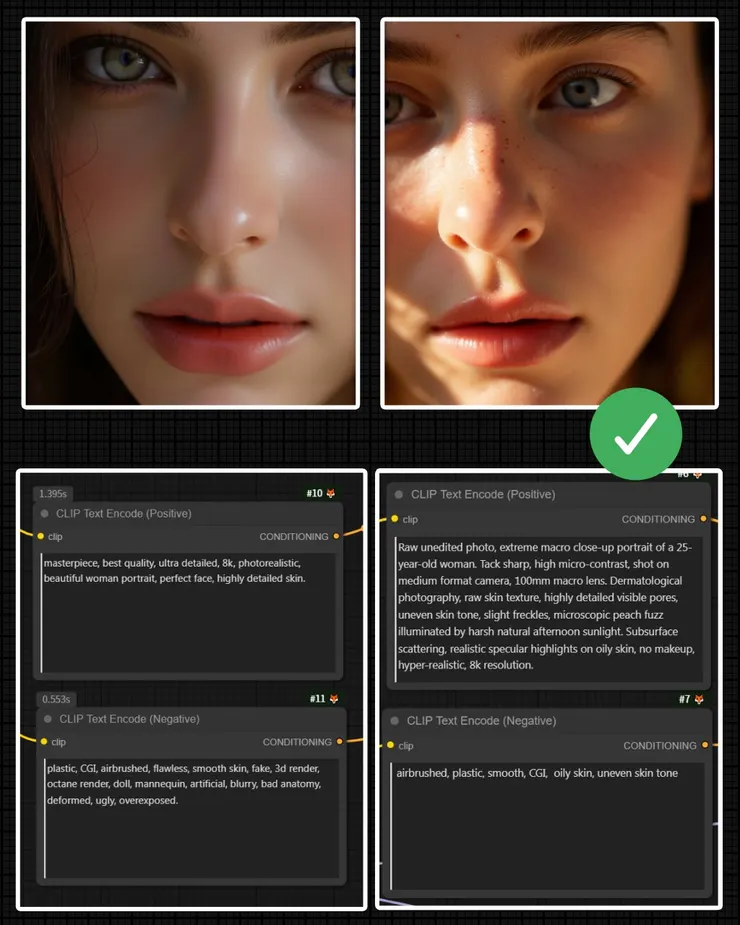
負面提示詞的本質是「排斥力 (Constraint by avoidance)」。當你在負面節點輸入「不要塑膠感 (not plastic)」時,你是在告訴 KSampler 將降噪路徑推離潛在空間中代表塑膠的區域。然而,潛在空間是極度龐大且多維的。當你設定了一個模糊的排斥區域,模型確實遠離了塑膠,但它可能被推向木頭、金屬、過度銳化的噪點,或是任何未知的邊界。這就是為何過度依賴負面提示詞會導致產出極度不穩定的根本原因:你只定義了「不要去哪裡」,卻沒有給予明確的「目的地」。
相反地,採用「正面物理屬性描述」則是建立強大的「吸引力 (Constraint by attraction)」。與其用空泛的形容詞描述你想要的臉孔,不如直接描述皮膚表面的物理構成。例如,在正面 `CLIP Text Encode` 節點中輸入:「表皮的半透明質 (the translucent quality of the epidermis)」、「特定區域微血管透出的溫度影響 (warmth from blood vessels underneath)」、「額頭與臉頰的毛孔密度差異 (pore density differs between forehead and cheek)」,以及「底層骨骼結構如何影響鼻樑的受光 (how the nose bridge catches light differently because of the underlying bone structure)」。
這種做法的底層邏輯在於,這些精確的物理與解剖學詞彙,在 CLIP 模型的訓練資料庫中,對應著極度具體且狹窄的潛在空間座標。你不再是要求模型「避開壞區域」,而是強制它「精準降落在此座標」。在 KSampler 的運算中,這種強大的正向吸引向量,能輕易覆蓋掉隨機噪聲帶來的偏差。
此外,這裡存在一個關鍵的防禦性盲點:CFG Scale (Classifier-Free Guidance Scale) 的連動控制。當你採用強烈的正面物理引導時,模型已經具備極高的方向確定性。此時,你必須適度調降 KSampler 中的 CFG Scale 數值。若維持過高的 CFG,模型會過度強化這些物理特徵,導致毛孔過度銳化或出現不自然的色斑。精準的提示詞配合克制的 CFG 數值,才是確保 `LATENT` 轉譯為 `IMAGE` 時不出錯的鐵律。
## 實務落地與商業槓桿
將這套底層邏輯應用於實務工作流中,能產生巨大的商業槓桿效應。在建構 ComfyUI 的自動化渲染管線時,我們必須強制執行「節點隔離與極簡化」的防禦性策略。
首先,徹底清空你那龐大且冗長的負面 `CLIP Text Encode` 節點。將其精簡到只保留最基礎的結構性防禦詞彙(如 extra limbs, deformed, bad anatomy)。將所有關於材質、光影、質感的控制權,全部轉移到正面提示詞節點中。
在商業接案的情境中,例如虛擬模特兒生成或產品情境圖的寫實人像合成,這種架構重組能帶來非線性的效率增長。過去,為了確保不同服裝或姿勢下的皮膚質感一致,技術人員必須針對每一張圖片進行客製化的負面提示詞微調,這是一項耗時數小時的手動勞力。
現在,透過建立模組化的「物理屬性正向提示詞庫」,你可以將這些精準的皮膚描述封裝成一個獨立的 Text 節點,並透過 `Conditioning (Combine)` 節點與主體描述無縫接軌。這種防禦性工作流具備極高的抗干擾能力。無論你如何抽換主體的動作、場景或隨機種子 (Seed),強大的物理吸引向量都能確保皮膚渲染的品質穩定輸出。
這不僅是將原本需要數週的試錯期降維成一鍵生成的自動化流程,更是將技術人員的價值,從「低階的參數修補工」,提升為「精準控制潛在空間的架構師」。當你的工作流不再因為微小的變數而崩潰時,你才能真正實現批次生成與 API 自動化串接的商業變現,徹底打破勞力密集的線性增長極限。
👉『加入沙龍/訂閱電子報』,獲取更多技術解法。
[Note_Leon3D: recN1RTQjvWHuvycT]




















