台積電於 2026 年台灣技術論壇上,不僅揭示了半導體市場在 AI 驅動下的驚人成長曲線,更正式宣告 2 奈米製程進入量產,並同步公開了由先進封裝交織而成的晶片堆疊藍圖。本次論壇傳遞出一個明確訊號:台積電正在將製程微縮、三維封裝與 AI 運算需求深度融合,構築一個從晶圓製造到系統整合的全新生態霸權。
一、AI 市場飛輪成形:從晶片到 Token 的價值重構
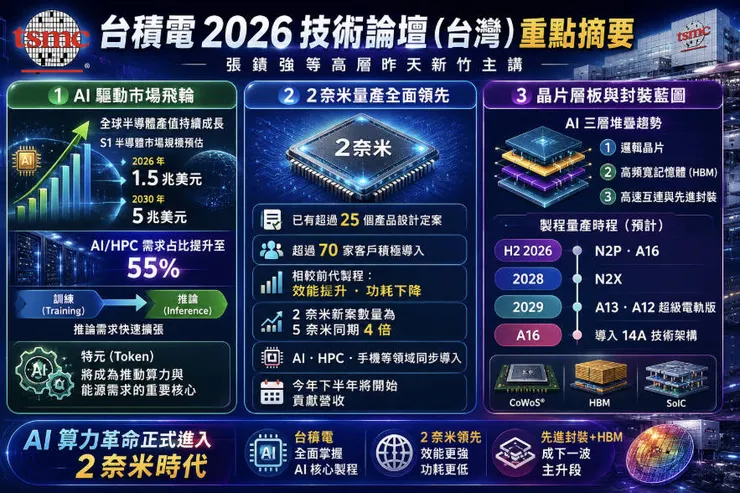
台積電會中預估,全球半導體市場規模將從 2026 年的約 1.5 兆美元,高速攀升至 2030 年的約 5 兆美元。驅動此爆發性成長的核心動能,在於 AI 與高效能運算需求占比將一舉拉高至 55%,徹底翻轉過去由消費性電子主導的產業結構。
更關鍵的轉折在於「推論需求」的快速擴張。隨著大型語言模型從訓練階段邁向商業化部署,AI 推理工作負載正以指數級增長,台積電明確點出「特元」將成為推動算力與能源需求的核心單位。所謂特元,即模型輸入輸出的最小語意單元,每一次的生成式 AI 對話、程式碼輔助或圖像創作,都意味著數百至數千個 Token 的即時運算。這股需求不僅對邏輯晶片的能耗比提出更嚴苛要求,也使得先進製程的經濟效益被重新定價——更省電的電晶體即代表更低的每 Token 成本,從而激發更大規模的應用,形成需求飛輪。台積電製程的能效領先,正是撬動此飛輪的關鍵槓桿。
二、2 奈米全面量產:GAA 時代的壓倒性領先
論壇最受矚目的里程碑,無疑是 2 奈米製程正式量產。台積電宣布該節點已有超過 25 個產品設計定案,逾 70 家客戶積極導入,且新案數量達到 5 奈米同期的 4 倍之多,並將於 2026 下半年開始貢獻營收。這組數字極具戰略意義:它代表 2 奈米不僅是技術展示,更已成為全球頂尖晶片設計公司爭相卡位的量產平台。
2 奈米採用奈米片電晶體架構,相較前代在效能與功耗上皆有顯著躍進。定案數量的懸殊差距(與 5 奈米同期相比),反映業界在 AI 算力軍備競賽下,對最先進製程的依賴不減反增,且轉換速度更為激進。當競爭對手仍在改良第一代 GAA 良率之際,台積電已能將 2 奈米推向大規模量產,並獲得「營收貢獻」,這意味著其良率與產能已跨過經濟門檻,量產曲線的斜率將大幅拉開與追趕者的距離,進一步鞏固其在 AI 半導體的獨家供應地位。
三、三層堆疊與封裝藍圖:從平面微縮走向系統整合
除了邏輯製程,台積電也描繪出因應 AI 的「三層堆疊」大趨勢:底層的邏輯運算晶片、中間層的高頻寬記憶體,以及貫穿全系統的高速互連與先進封裝。這三者已不再是獨立零組件,而是必須同步優化的整合體。
會中揭露的詳細量產節點路徑,可看出台積電如何以精密節奏推進此一整合:
2026 下半年:同時量產 N2P(2 奈米性能增強版)與 A16 製程。其中 A16 最大亮點在於導入原屬 14A 世代的技術架構,即超級電軌背面供電網路。這使得 A16 在 1.6 奈米級別便提前實現了將電源網路移至晶片背面的革命性設計,能同時解放訊號互連密度並大幅降低 IR 壓降,專為功耗極度敏感的 AI 推論晶片所設計。
2028 年:推出 N2X,應是為滿足高速運算對極致效能的進一步壓榨,可能強化驅動電流或針對特定 HPC 負載優化。
2029 年:進入 A13 與 A12 超級電軌版。A12 超級電軌版的名稱,暗示在 1.2 奈米節點上,背面供電技術將進化至更全面的「超級電軌」,實現奈米級垂直供電網路,與正面奈米片電晶體構成完美的三維供電與運算結構。
此路線圖傳達的核心訊息是:台積電已將先進封裝與製程微縮視為一體兩面。CoWoS 與 SoIC 等封裝技術,讓 HBM 能在最短距離內與邏輯晶片進行三維堆疊,而 A16 等特殊節點的誕生,正是為了讓這類堆疊架構達到最佳能效。未來 AI 晶片的競爭力,將不再由單一電晶體密度決定,而是由「邏輯-記憶體-互連」的整體系統功耗與頻寬效率來定義,台積電正透過縝密的節點與封裝藍圖,為客戶鋪設好一條從晶片到系統的完整軌道。
結語
台積電 2026 技術論壇所揭露的,遠不止於單一製程的突破,而是一套完整的 AI 運算時代解決方案。從以 Token 經濟錨定市場需求,到 2 奈米量產席捲客戶設計定案,再到 A16 率先嫁接背面供電與長遠的 A12 超級電軌版布局,台積電已將技術領先的維度從晶圓製造擴張至三維系統級整合。在 AI 驅動半導體產值直衝 5 兆美元的路上,這套綿密的技術織網,正將台積電的競爭壁壘推向前所未有的高度。